
반응형

1. 개요
Mean Shift는 군집 개수를 사전에 지정하지 않는 군집화 알고리즘입니다.
K-Means처럼 “K를 몇 개로 할 것인가?”를 고민할 필요 없이,
데이터 분포 자체를 기준으로 군집 중심을 자동으로 탐색합니다.
Mean Shift의 핵심은 KDE(Kernel Density Estimation, 커널 밀도 추정) 입니다.
즉, 데이터가 가장 밀집된 방향으로 반복적으로 이동하면서
자연스럽게 군집 중심에 수렴하도록 설계된 알고리즘입니다.
1. 개요
Mean Shift는 군집 개수를 사전에 지정하지 않는 군집화 알고리즘입니다.
K-Means처럼 “K를 몇 개로 할 것인가?”를 고민할 필요 없이,
데이터 분포 자체를 기준으로 군집 중심을 자동으로 탐색합니다.
Mean Shift의 핵심은 KDE(Kernel Density Estimation, 커널 밀도 추정) 입니다.
즉, 데이터가 가장 밀집된 방향으로 반복적으로 이동하면서
자연스럽게 군집 중심에 수렴하도록 설계된 알고리즘입니다.
2. Mean Shift 핵심 아이디어 정리
2-1. Mean Shift의 동작 방식
Mean Shift는 다음 과정을 모든 데이터 포인트에 대해 반복 수행합니다.
- 특정 데이터 포인트를 기준으로 반경(bandwidth) 설정
- 해당 반경 내 데이터들의 확률 밀도(KDE) 계산
- 밀도가 가장 높은 방향으로 중심점 이동(mean shift)
- 이동된 위치에서 다시 반경 내 밀도 계산
- 더 이상 이동하지 않으면 수렴(군집 중심)
- 모든 데이터에 대해 수행 → 군집 형성
👉 군집 개수는 결과적으로 자동 결정됩니다.
2-2. Mean Shift의 핵심 파라미터: Bandwidth
- bandwidth가 클수록
- 반경이 넓어짐
- 군집 중심 수 ↓
- 군집이 거칠어짐
- bandwidth가 작을수록
- 반경이 좁아짐
- 군집 중심 수 ↑
- 군집이 세분화됨
👉 Mean Shift의 성능은 Bandwidth 설정에 거의 전적으로 의존합니다.
3. KDE(Kernel Density Estimation) 이해
3-1. KDE란?
KDE는 확률 밀도 함수(PDF) 를 데이터로부터 직접 추정하는 방법입니다.
- 특정 분포(정규분포 등)를 가정하지 않음
- 관측된 데이터만으로 확률 밀도 추정
- 비모수적 추정 방식
모수적 vs 비모수적
- 모수적 추정: 데이터가 특정 분포를 따른다고 가정 (GMM 등)
- 비모수적 추정: 분포 가정 없이 데이터로 밀도 추정 (KDE)
3-2. 히스토그램 기반 밀도 추정의 문제점
- Bin 경계에서 불연속성 발생
- Bin 크기에 따라 결과가 크게 달라짐
👉 KDE는 이러한 문제를 커널 함수(주로 Gaussian) 로 해결합니다.
4. KDE 시각화 실습
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set(color_codes=True)
np.random.seed(0)
# 평균 0, 표준편차 1을 가지는 정규분포 데이터 30개 생성
x = np.random.normal(0, 1, size=30)
print(x)
# 히스토그램 + KDE 곡선 시각화
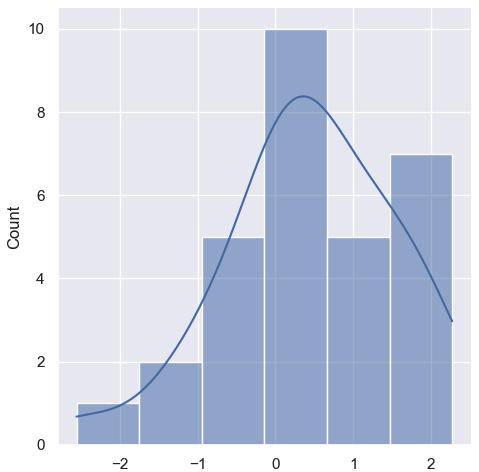
sns.displot(x, kde=True)👉
- 히스토그램 위에 부드러운 확률 밀도 곡선이 함께 표현됩니다.
# 히스토그램만 표현
sns.displot(x, kde=False, rug=True)👉
- Bin 경계가 뚜렷하여 분포가 거칠게 보입니다.

# KDE만 표현
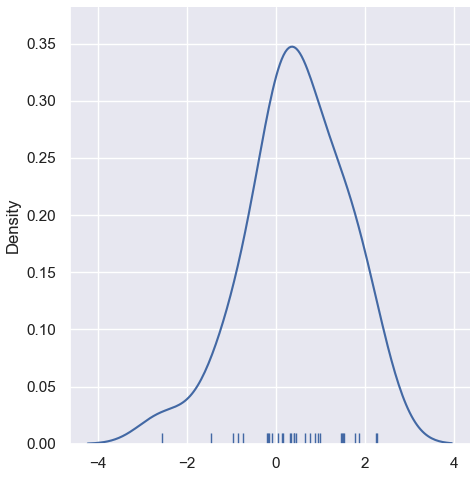
sns.displot(x, kind="kde", rug=True)👉
- KDE는 데이터 분포를 연속적이고 부드럽게 표현합니다.
- Mean Shift는 바로 이 KDE를 기반으로 군집화를 수행합니다.
5. Mean Shift 군집화 실습 (사이킷런)
5-1. make_blobs()로 군집용 데이터 생성
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import MeanShift
# 2차원, 3개 군집 중심을 가지는 데이터 200개 생성
X, y = make_blobs(
n_samples=200,
n_features=2,
centers=3,
cluster_std=0.8,
random_state=0
)👉
- y는 정답 레이블이지만
- Mean Shift는 비지도 학습이므로 사용하지 않음
5-2. Bandwidth = 0.9 로 Mean Shift 수행
meanshift = MeanShift(bandwidth=0.9)
cluster_labels = meanshift.fit_predict(X)
print(f'cluster labels 유형 : {np.unique(cluster_labels)}')
#cluster labels 유형 : [0 1 2 3 4 5 6 7]👉 해석
- bandwidth가 너무 작아
- 데이터가 과도하게 분할됨
- 군집 개수 8개로 증가 → 과분할
5-3. Bandwidth = 1 로 증가 후 재실행
meanshift = MeanShift(bandwidth=1)
cluster_labels = meanshift.fit_predict(X)
print(f'cluster labels 유형 : {np.unique(cluster_labels)}')
cluster labels 유형 : [0 1 2]👉
- 실제 데이터 생성 시 설정한 군집 개수(3)와 일치
- bandwidth 조정의 중요성을 확인 가능
6. 최적 Bandwidth 자동 추정
6-1. estimate_bandwidth() 사용
from sklearn.cluster import estimate_bandwidth
bandwidth = estimate_bandwidth(X, quantile=0.25)
print(f'bandwidth 값 : {round(bandwidth,3)}')
bandwidth 값 : 1.689👉
- 데이터 분포를 기반으로 적절한 bandwidth 자동 계산
- 실무에서 매우 자주 사용됨
6-2. 최적 Bandwidth 기반 Mean Shift 재수행
import pandas as pd
clusterDF = pd.DataFrame(
data=X,
columns=['ftr1','ftr2']
)
clusterDF['target'] = y
best_bandwidth = estimate_bandwidth(X, quantile=0.25)
meanshift = MeanShift(bandwidth=best_bandwidth)
cluster_labels = meanshift.fit_predict(X)
print(f'cluster labels 유형 : {np.unique(cluster_labels)}')
cluster labels 유형 : [0 1 2]👉
- 군집 개수가 자동으로 3개로 안정적으로 수렴
7. Mean Shift 군집 결과 시각화
import matplotlib.pyplot as plt
%matplotlib inline
clusterDF['meanshift_label'] = cluster_labels
centers = meanshift.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers=['o', 's', '^', 'x', '*']
for label in unique_labels:
label_cluster = clusterDF[clusterDF['meanshift_label']==label]
center_x_y = centers[label]
# 군집별 데이터 포인트 시각화
plt.scatter(
x=label_cluster['ftr1'],
y=label_cluster['ftr2'],
edgecolor='k',
marker=markers[label]
)
# 군집 중심점 시각화
plt.scatter(
x=center_x_y[0],
y=center_x_y[1],
s=200,
color='white',
edgecolor='k',
alpha=0.9,
marker=markers[label]
)
plt.scatter(
x=center_x_y[0],
y=center_x_y[1],
s=70,
color='k',
edgecolor='k',
marker='$%d$' % label
)
plt.show()👉
- 군집 중심이 데이터 밀집 영역 중심에 정확히 위치
- Mean Shift의 특성이 시각적으로 명확히 드러남

7-1. 실제 타깃과 Mean Shift 결과 비교
print(clusterDF.groupby('target')['meanshift_label'].value_counts())
target meanshift_label
0 0 67
1 2 67
2 1 65
2 1👉
- 대부분의 데이터가 정확히 대응됨
- 일부 경계 데이터만 혼합됨
8. 결론 정리
- Mean Shift는 군집 개수를 사전에 지정하지 않는 강력한 군집화 알고리즘입니다.
- KDE 기반으로 데이터 분포 중심을 직접 탐색합니다.
- Bandwidth 설정이 성능의 핵심이며,
- 너무 작으면 과분할
- 너무 크면 과도한 통합 발생
- estimate_bandwidth()를 활용하면 실무 적용이 수월합니다.
- 단점
- 데이터 수가 많을 경우 연산 비용이 큼
- 고차원 데이터에서는 성능 저하 가능
👉 중소 규모 데이터 + 분포 기반 군집화가 필요한 경우 매우 유용한 알고리즘입니다.
반응형
'Programming' 카테고리의 다른 글
| DBSCANDensity-Based Spatial Clustering of Applications with Noise (0) | 2026.01.12 |
|---|---|
| Gaussian Mixture Model(GMM) 군집화– K-Means의 한계를 극복하는 확률 기반 군집 알고리즘 (0) | 2026.01.12 |
| K-Means 군집 성능 평가를 위한 실루엣(Silhouette) 분석 완전 이해 (0) | 2026.01.12 |
| K-Means 군집화 실험을 위한 인공 데이터 생성과 중심점 시각화 (0) | 2026.01.12 |
| 군집화(Clustering) 개념과 K-Means 알고리즘 실습 정리 (0) | 2026.01.12 |