
반응형

1. 개요
K-Means는 거리 기반 군집화 알고리즘으로,
군집이 원형(spherical) 이고 중심점을 기준으로 고르게 퍼져 있을 때 매우 효과적입니다.
하지만 실제 데이터는 다음과 같은 경우가 많습니다.
- 군집이 길게 늘어진 타원형 분포
- 군집마다 분산 크기가 서로 다름
- 중심 거리보다 분포 형태가 중요한 경우
이러한 상황에서는 K-Means가 군집을 잘못 나누는 문제가 발생합니다.
이를 해결하기 위해 등장한 알고리즘이 Gaussian Mixture Model(GMM) 입니다.
2. K-Means의 구조적 한계
K-Means의 핵심 가정
- 각 군집은 하나의 중심점(Centroid) 을 가짐
- 모든 군집은 유사한 크기와 분산
- 거리(Euclidean Distance)가 군집 결정의 기준
👉 결과적으로 원형 군집에는 강하지만,
타원형·비대칭 분포에는 취약합니다.
3. Gaussian Mixture Model(GMM) 개념 이해
3-1. GMM이란?
GMM은 데이터를 다음과 같이 가정합니다.
“전체 데이터는 여러 개의 가우시안(정규) 분포가 섞여 있는 혼합 모델이다.”
즉,
- 하나의 군집 = 하나의 정규분포
- 전체 데이터 = 여러 정규분포의 혼합(Mixture)
3-2. GMM의 핵심 아이디어
- 각 데이터는 어떤 군집에 속할 확률을 가짐
- 군집 할당은 확률 기반(soft assignment)
👉 K-Means는 “가장 가까운 군집 1개”만 선택
👉 GMM은 “각 군집에 속할 확률”을 계산
4. EM(Expectation–Maximization) 알고리즘
GMM은 EM 알고리즘을 이용해 모수를 추정합니다.
(1) E-step (Expectation)
- 각 데이터가 각 가우시안 분포에 속할 확률 계산
- 가장 높은 확률을 가진 분포에 임시 할당
(2) M-step (Maximization)
- 할당된 데이터를 기반으로
- 평균(mean)
- 분산(covariance)
- 혼합 확률(weight)
- 가능도를 최대화하도록 모수 재계산
(3) 수렴 조건
- 평균·분산이 더 이상 변하지 않음
- 데이터 소속이 더 이상 변경되지 않음
👉 수렴 시 최종 군집 확정
5. 붓꽃 데이터셋 GMM 군집화 실습
5-1. 데이터 로딩 및 DataFrame 생성
import pandas as pd
from sklearn.datasets import load_iris
# 붓꽃 데이터 로드
iris = load_iris()
# 피처명 지정
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# DataFrame 생성
irisDF = pd.DataFrame(
data=iris.data,
columns=feature_names
)
# 실제 타깃 값 추가 (비교용)
irisDF['target'] = iris.target👉
- target은 정답 레이블
- GMM은 비지도 학습이므로 학습에는 사용하지 않음
5-2. GMM 군집화 수행
from sklearn.mixture import GaussianMixture
# 3개의 가우시안 분포를 가진 GMM 생성 및 학습
gmm = GaussianMixture(
n_components=3, # 군집 개수
random_state=0
).fit(iris.data)
# 각 데이터의 군집 예측
gmm_cluster_labels = gmm.predict(iris.data)
# 결과를 DataFrame에 저장
irisDF['gmm_cluster'] = gmm_cluster_labels5-3. 실제 타깃과 GMM 결과 비교
iris_result = irisDF.groupby(['target'])['gmm_cluster'].value_counts()
print(iris_result)
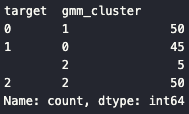
target gmm_cluster
0 1 50
1 0 45
2 5
2 2 50👉
- Setosa(0), **Virginica(2)**는 완벽하게 분리
- Versicolor(1) 일부만 혼합됨
- 전체적으로 K-Means보다 안정적
6. 동일 데이터에 K-Means 적용 비교
from sklearn.cluster import KMeans
kmeans = KMeans(
n_clusters=3,
init='k-means++',
max_iter=300,
random_state=0
).fit(iris.data)
kmeans_cluster_labels = kmeans.predict(iris.data)
irisDF['kmeans_cluster'] = kmeans_cluster_labels
iris_result = irisDF.groupby(['target'])['kmeans_cluster'].value_counts()
print(iris_result)
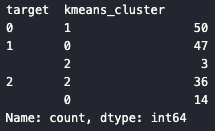
target kmeans_cluster
0 1 50
1 0 47
2 3
2 2 36
0 14👉
- Virginica(2) 군집에서 오분류 증가
- 타원형 분포를 제대로 반영하지 못함
7. 군집 결과 시각화 함수 정의
def visualize_cluster_plot(clusterobj, dataframe, label_name, iscenter=True):
"""
clusterobj : 학습된 클러스터링 객체
dataframe : 피처 + 클러스터 결과를 가진 DataFrame
label_name : 클러스터 라벨 컬럼명
iscenter : 중심점 표시 여부
"""
if iscenter:
centers = clusterobj.cluster_centers_
unique_labels = np.unique(dataframe[label_name].values)
markers = ['o', 's', '^', 'x', '*']
isNoise = False
for label in unique_labels:
label_cluster = dataframe[dataframe[label_name] == label]
if label == -1:
cluster_legend = 'Noise'
isNoise = True
else:
cluster_legend = 'Cluster ' + str(label)
plt.scatter(
x=label_cluster['ftr1'],
y=label_cluster['ftr2'],
s=70,
edgecolor='k',
marker=markers[label],
label=cluster_legend
)
if iscenter:
center_x_y = centers[label]
plt.scatter(
x=center_x_y[0],
y=center_x_y[1],
s=250,
color='white',
edgecolor='k',
alpha=0.9,
marker=markers[label]
)
plt.scatter(
x=center_x_y[0],
y=center_x_y[1],
s=70,
color='k',
edgecolor='k',
marker='$%d$' % label
)
plt.legend(loc='upper right')
plt.show()👉
- K-Means, DBSCAN, GMM 모두 재사용 가능
- GMM은 중심점 개념이 없으므로 iscenter=False
8. 타원형 데이터 생성 및 비교 실험
8-1. 타원형 데이터 생성
from sklearn.datasets import make_blobs
import numpy as np
X, y = make_blobs(
n_samples=300,
n_features=2,
centers=3,
cluster_std=0.5,
random_state=0
)
# 타원형 변환 적용
transformation = [[0.60834549, -0.63667341],
[-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation)
clusterDF = pd.DataFrame(
data=X_aniso,
columns=['ftr1', 'ftr2']
)
clusterDF['target'] = y
# 실제 타깃 시각화
visualize_cluster_plot(None, clusterDF, 'target', iscenter=False)
8-2. K-Means 적용
kmeans = KMeans(3, random_state=0)
kmeans_label = kmeans.fit_predict(X_aniso)
clusterDF['kmeans_label'] = kmeans_label
visualize_cluster_plot(kmeans, clusterDF, 'kmeans_label', iscenter=True)
8-3. GMM 적용
gmm = GaussianMixture(n_components=3, random_state=0)
gmm_label = gmm.fit(X_aniso).predict(X_aniso)
clusterDF['gmm_label'] = gmm_label
visualize_cluster_plot(gmm, clusterDF, 'gmm_label', iscenter=False)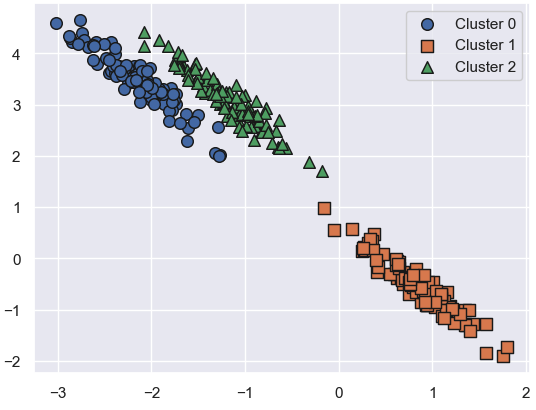
8-4. 정량적 비교 결과
print('### KMeans Clustering ###')
print(clusterDF.groupby('target')['kmeans_label'].value_counts())
print('\n### Gaussian Mixture Clustering ###')
print(clusterDF.groupby('target')['gmm_label'].value_counts())
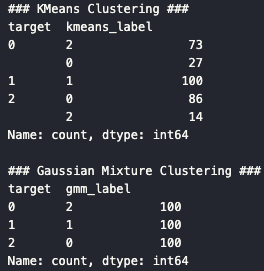
### KMeans Clustering ###
target kmeans_label
0 2 73
0 27
1 1 100
2 0 86
2 14
### Gaussian Mixture Clustering ###
target gmm_label
0 2 100
1 1 100
2 0 100👉 GMM이 완벽하게 분리 성공
9. 결론 정리
- K-Means
- 빠르고 단순
- 원형 군집에 적합
- 거리 기반 한계 존재
- GMM
- 확률 기반 군집화
- 타원형·비대칭 분포에 강함
- EM 알고리즘 기반
👉 실제 데이터가 정규분포 혼합 형태라면 GMM이 훨씬 안정적인 선택입니다.
반응형
'Programming' 카테고리의 다른 글
| 고객 세그먼테이션 구현 실습RFM 기법 + K-Means 군집화 (0) | 2026.01.12 |
|---|---|
| DBSCANDensity-Based Spatial Clustering of Applications with Noise (0) | 2026.01.12 |
| Mean Shift 군집화 완전 이해– KDE 기반 자동 군집 개수 결정 알고리즘 (0) | 2026.01.12 |
| K-Means 군집 성능 평가를 위한 실루엣(Silhouette) 분석 완전 이해 (0) | 2026.01.12 |
| K-Means 군집화 실험을 위한 인공 데이터 생성과 중심점 시각화 (0) | 2026.01.12 |