
반응형
1. 개요
군집화 알고리즘은 정답(label)이 없는 데이터에서 패턴을 찾기 때문에,
알고리즘의 동작 원리를 명확히 이해하기 위해서는 통제된 데이터로 실험하는 것이 매우 중요합니다.
이번 글에서는
- make_blobs()를 이용해 의도적으로 군집 구조가 있는 데이터를 생성하고
- K-Means 알고리즘이 어떻게 중심점을 찾고 군집을 형성하는지
- 그리고 군집 중심(Centroid)이 시각적으로 어떻게 이동·결정되는지
를 단계적으로 확인합니다.
2. Clustering 알고리즘 테스트용 데이터 생성 파라미터 이해
Clustering 실험을 위해 사이킷런은 make_blobs()라는 함수를 제공합니다.
주요 파라미터 설명
- n_samples
생성할 전체 데이터 개수입니다. 기본값은 100이며, 실험 규모를 조절할 때 사용합니다. - n_features
데이터의 피처 개수입니다.
시각화를 목표로 할 경우 보통 2로 설정하여 X, Y 좌표로 표현합니다. - centers
군집의 개수를 의미합니다.
정수로 주면 해당 개수만큼 중심점을 자동 생성합니다. - cluster_std
각 군집 내부 데이터의 퍼짐 정도(표준편차)를 의미합니다.
값이 클수록 군집이 퍼지고, 작을수록 조밀해집니다.
3. 인공 군집 데이터 생성
# Clustering 알고리즘 테스트를 위한 데이터 생성
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
%matplotlib inline👉
- 군집 데이터 생성을 위한 make_blobs
- 군집화를 위한 KMeans
- 시각화를 위한 matplotlib
을 불러옵니다.
# 인공 클러스터 데이터 생성
# X: 특성 데이터 (좌표)
# y: 실제 클러스터 레이블 (정답, 비지도 학습에서는 보통 사용하지 않음)
X, y = make_blobs(
n_samples=200, # 총 데이터 개수
n_features=2, # 2차원 데이터 (시각화 목적)
centers=3, # 3개의 군집
cluster_std=0.8, # 군집 내 데이터 퍼짐 정도
random_state=0 # 재현 가능한 결과를 위한 시드
)👉
- 총 200개의 데이터 포인트를 생성합니다.
- 2차원이므로 평면상에 점으로 표현할 수 있습니다.
- 실제로는 3개의 군집 구조를 가지도록 설계된 데이터입니다.
- y는 우리가 만든 정답 군집 정보이며, K-Means 학습에는 사용하지 않습니다.
print(X.shape, y.shape)👉
- X: (200, 2) → 데이터 200개, 피처 2개
- y: (200,) → 각 데이터의 실제 군집 레이블
# y target값 분포 확인
unique, counts = np.unique(y, return_counts=True)
print(unique, counts)👉
- 각 군집에 몇 개의 데이터가 포함되어 있는지 확인합니다.
- 군집이 거의 균등하게 생성되었음을 알 수 있습니다.
4. 데이터프레임 구성 및 원본 데이터 시각화
import pandas as pd
clusterDF = pd.DataFrame(
data=X,
columns=['ftr1','ftr2']
)
clusterDF['target'] = y
clusterDF.head(10)👉
- 생성된 데이터를 DataFrame 형태로 관리합니다.
- target 컬럼은 비교용이며, 군집화에는 사용하지 않습니다.

# make_blobs()으로 만들어진 데이터 포인트 시각화
target_list = np.unique(y)
# 각 target별 scatter plot marker 설정
markers = ['o','s','^','p','D','H','x']
for target in target_list:
target_cluster = clusterDF[clusterDF['target']==target]
plt.scatter(
x=target_cluster['ftr1'],
y=target_cluster['ftr2'],
edgecolors='k',
marker=markers[target]
)
plt.show()👉
- 실제 군집 정답 기준으로 데이터를 시각화합니다.
- 육안으로도 3개의 군집 구조가 존재함을 확인할 수 있습니다.
- 하지만 중심점 위치는 아직 명확하지 않습니다.
5. K-Means 군집화 수행
# KMeans 클러스터링 수행
kmeans = KMeans(
n_clusters=3,
init='k-means++',
max_iter=200,
random_state=0
)
cluster_labels = kmeans.fit_predict(X)
clusterDF['kmeans_label'] = cluster_labels👉
- 군집 개수는 3으로 지정합니다.
- k-means++는 초기 중심점을 안정적으로 설정하기 위한 방식입니다.
- fit_predict()는 학습과 동시에 군집 할당 결과를 반환합니다.
# 군집 중심 좌표 추출
centers = kmeans.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers = ['o','s','^','P','D','H','x']👉
- cluster_centers_는 각 군집의 최종 중심점 좌표입니다.
- 시각화를 위해 군집 라벨과 마커를 준비합니다.
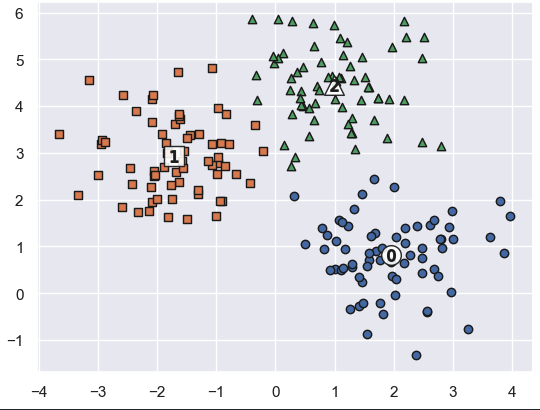
6. 군집 결과와 중심점 시각화
# 군집화된 결과 시각화
for label in unique_labels:
label_cluster = clusterDF[clusterDF['kmeans_label']==label]
center_x_y = centers[label]
# 군집에 속한 데이터 포인트 시각화
plt.scatter(
x=label_cluster['ftr1'],
y=label_cluster['ftr2'],
edgecolor='k',
marker=markers[label]
)
# 군집 중심점 시각화 (큰 원)
plt.scatter(
x=center_x_y[0],
y=center_x_y[1],
s=200,
color='white',
alpha=0.9,
edgecolors='k',
marker=markers[label]
)
# 군집 중심점 번호 표시
plt.scatter(
x=center_x_y[0],
y=center_x_y[1],
s=70,
color='k',
alpha=0.9,
edgecolors='k',
marker='$%d$'%label
)👉
- 각 군집의 데이터 분포와
- 해당 군집의 중심점(Centroid) 을 함께 시각화합니다.
- 숫자는 군집 라벨을 의미합니다.
print(clusterDF.groupby('target')['kmeans_label'].value_counts())👉
- 실제 군집(target)과 K-Means 결과(kmeans_label)를 비교합니다.
- 대부분의 데이터가 올바르게 군집화되었음을 확인할 수 있습니다.
- 일부 경계 데이터는 다른 군집으로 분류될 수 있습니다.

7. 결론
- make_blobs()는 군집 알고리즘 실험용 데이터 생성에 매우 유용합니다.
- K-Means는 군집 중심점을 반복적으로 이동시키며 군집을 형성합니다.
- 중심점 시각화를 통해 알고리즘의 동작 원리를 직관적으로 이해할 수 있습니다.
- 실제 데이터에서는
👉 차원 축소(PCA),
👉 스케일링,
👉 이상치 처리
와 함께 사용하는 것이 중요합니다.
반응형
'Programming' 카테고리의 다른 글
| Mean Shift 군집화 완전 이해– KDE 기반 자동 군집 개수 결정 알고리즘 (0) | 2026.01.12 |
|---|---|
| K-Means 군집 성능 평가를 위한 실루엣(Silhouette) 분석 완전 이해 (0) | 2026.01.12 |
| 군집화(Clustering) 개념과 K-Means 알고리즘 실습 정리 (0) | 2026.01.12 |
| 차원 축소(Dimension Reduction) 완전 정리 요약PCA · LDA · SVD · Truncated SVD · NMF (0) | 2026.01.11 |
| SVD(Singular Value Decomposition, 특이값 분해) 이해하기 (0) | 2026.01.11 |