

1. 개요
군집화(Clustering)는 라벨이 없는 데이터를 대상으로,
데이터 포인트 간의 유사성(similarity) 을 기준으로 여러 개의 그룹(군집)으로 나누는 비지도 학습 기법입니다.
지도학습처럼 정답(label)이 존재하지 않기 때문에,
“무엇이 비슷한가?”, “어떤 기준으로 묶을 것인가?”가 핵심이 됩니다.
본 글에서는
- 군집화의 기본 개념
- 대표적인 군집 알고리즘
- K-Means 알고리즘의 동작 원리
- 붓꽃(Iris) 데이터셋을 활용한 K-Means 실습과 시각화
를 단계적으로 정리합니다.
2. 군집화(Clustering)란 무엇인가?
군집화란 데이터 포인트들을 여러 개의 군집(Cluster)으로 그룹화하는 작업을 의미합니다.
🔹 군집화의 핵심 목적
- 같은 군집 내부의 데이터들은 서로 유사
- 서로 다른 군집 간 데이터들은 상이
즉,
👉 군집 내부 유사성은 최대화, 군집 간 유사성은 최소화하는 것이 목표입니다.
3. 군집화 활용 분야
군집화는 실무 및 연구에서 매우 폭넓게 활용됩니다.
- 고객 세분화, 마켓/브랜드/사회경제 활동 분석
- 이미지 검출, 세분화(Segmentation), 트래킹
- 이상 탐지(Outlier Detection)
- 추천 시스템의 사용자/아이템 그룹화
4. 군집화에서 가장 중요한 질문
“유사성을 어떻게 정의할 것인가?”
대부분의 군집 알고리즘은
- 거리(distance)
- 밀도(density)
- 확률 분포(distribution)
중 하나를 기준으로 유사성을 판단합니다.
5. 대표적인 군집 알고리즘
① K-Means
- 군집 중심점(Centroid) 기반
- 가장 대표적이고 널리 사용됨
② Mean Shift
- 데이터 밀도가 높은 영역을 중심으로 군집 형성
③ Gaussian Mixture Model (GMM)
- 데이터가 여러 개의 정규분포 혼합으로 구성되었다고 가정
④ DBSCAN
- 밀도 기반 군집
- 이상치 탐지에 매우 강함
6. K-Means 알고리즘 원리
K-Means는 군집 중심점(Centroid) 을 기준으로 동작합니다.
🔁 반복 절차
- 군집 개수 K를 지정
- K개의 초기 중심점 설정
- 각 데이터 포인트를 가장 가까운 중심점에 할당
- 각 군집에 속한 데이터들의 평균으로 중심점 재계산
- 중심점 이동 후에도 소속 변경이 없으면 종료
✔ 장점
- 알고리즘이 단순하고 직관적
- 대용량 데이터 처리 가능
- 실무에서 가장 많이 사용
❌ 단점
- 거리 기반 → 차원의 저주 영향
- 이상치(outlier)에 취약
- K 값을 사전에 지정해야 함
7. K-Means 주요 파라미터
- n_clusters : 군집 개수
- init : 초기 중심점 설정 방식 (k-means++ 권장)
- n_init : 서로 다른 초기값으로 반복 실행 횟수
- max_iter : 중심점 이동 최대 반복 횟수
- tol : 중심점 이동 허용 오차
- random_state : 재현성 확보용 시드 값
- algorithm : 군집 계산 알고리즘 방식
8. K-Means를 이용한 붓꽃(Iris) 데이터 군집화 실습
📌 데이터 로딩 및 전처리
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline👉 군집화에 필요한 라이브러리들을 불러옵니다.
iris = load_iris()
print(f'target name : {iris.target_names}')👉 붓꽃 데이터셋과 실제 품종 이름을 확인합니다.
※ K-Means는 target을 사용하지 않습니다.
irisDF = pd.DataFrame(
data=iris.data,
columns=['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
)
irisDF.head(5)👉 붓꽃 데이터의 피처들을 DataFrame 형태로 구성합니다.

📌 K-Means 모델 생성 및 학습
kmeans = KMeans(
n_clusters=3,
init='k-means++',
max_iter=300, # 군집 중심점이 최대 300번 이동
random_state=0
)
kmeans.fit(irisDF)👉
- 군집 개수는 실제 품종 수와 동일하게 3으로 설정
- k-means++로 초기 중심점을 안정적으로 설정

print(kmeans.labels_)👉 각 데이터 포인트가 할당된 군집 번호(label) 를 출력합니다.
※ 이는 실제 품종(target)과는 다른 값입니다.

kmeans.fit_predict(irisDF)👉 학습과 예측을 한 번에 수행합니다.

kmeans.fit_transform(irisDF)👉 각 데이터와 군집 중심점 간의 거리 값을 반환합니다.

📌 군집 결과와 실제 타겟 비교
irisDF['target'] = iris.target
irisDF['cluster'] = kmeans.labels_
irisDF.head(5)👉 실제 품종(target)과 군집 결과(cluster)를 함께 확인합니다.

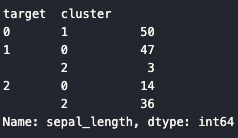
iris_result = irisDF.groupby(['target', 'cluster'])['sepal_length'].count()
print(iris_result)👉 각 실제 품종이 어떤 군집으로 얼마나 잘 묶였는지 확인합니다.
9. PCA를 이용한 군집 결과 시각화
군집 결과는 4차원이므로 바로 시각화가 어렵습니다.
따라서 PCA로 2차원 축소 후 시각화합니다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(iris.data)
irisDF['pca_x'] = pca_transformed[:, 0]
irisDF['pca_y'] = pca_transformed[:, 1]
irisDF.head(5)👉 PCA를 이용해 2차원 좌표를 생성합니다.

marker0_ind = irisDF[irisDF['cluster'] == 0].index
marker1_ind = irisDF[irisDF['cluster'] == 1].index
marker2_ind = irisDF[irisDF['cluster'] == 2].index👉 각 군집별 데이터 인덱스를 추출합니다.
plt.scatter(
x=irisDF.loc[marker0_ind, 'pca_x'],
y=irisDF.loc[marker0_ind, 'pca_y'],
marker='o'
)
plt.scatter(
x=irisDF.loc[marker1_ind, 'pca_x'],
y=irisDF.loc[marker1_ind, 'pca_y'],
marker='s'
)
plt.scatter(
x=irisDF.loc[marker2_ind, 'pca_x'],
y=irisDF.loc[marker2_ind, 'pca_y'],
marker='^'
)
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.title('3 Clusters Visualization by 2 PCA Components')
plt.show()👉 PCA 공간에서 군집이 어떻게 분리되었는지 시각적으로 확인할 수 있습니다.

10. 결론
- 군집화는 라벨이 없는 데이터에서 패턴을 발견하는 핵심 기법입니다.
- K-Means는 가장 기본적이면서도 실무 활용도가 매우 높습니다.
- 다만 거리 기반 알고리즘이므로
👉 차원 축소(PCA) 와 함께 사용하는 것이 중요합니다. - 군집 결과는 반드시 시각화 및 해석 단계를 거쳐야 의미를 가집니다.
'Programming' 카테고리의 다른 글
| K-Means 군집 성능 평가를 위한 실루엣(Silhouette) 분석 완전 이해 (0) | 2026.01.12 |
|---|---|
| K-Means 군집화 실험을 위한 인공 데이터 생성과 중심점 시각화 (0) | 2026.01.12 |
| 차원 축소(Dimension Reduction) 완전 정리 요약PCA · LDA · SVD · Truncated SVD · NMF (0) | 2026.01.11 |
| SVD(Singular Value Decomposition, 특이값 분해) 이해하기 (0) | 2026.01.11 |
| LDA(Linear Discriminant Analysis) – 분류를 위한 차원 축소 기법 (1) | 2026.01.11 |