
반응형

1. DBSCAN 개요
DBSCAN은 데이터의 밀도(density) 를 기반으로 군집을 형성하는 비지도 학습 알고리즘입니다.
K-Means나 GMM과 달리 군집 개수를 사전에 지정하지 않으며, 데이터 분포 자체를 보고 자동으로 군집을 탐색합니다.
특히 다음과 같은 데이터에서 강력한 성능을 보입니다.
- 복잡한 비선형 기하학 구조
- 원형이 아닌 고리형, 곡선형 분포
- 이상치(Noise)가 포함된 데이터
2. DBSCAN의 핵심 특징 정리
2-1. 장점
- 군집 개수 자동 결정
- 이상치(Noise)를 자연스럽게 탐지
- 복잡한 형태의 군집도 탐색 가능
2-2. 단점
- 데이터 밀도가 크게 다르거나 균일하면 성능 저하
- 피처 수가 많아질수록 거리 계산이 어려워짐
- eps, min_samples 설정에 민감
3. DBSCAN의 핵심 개념 정의 (매우 중요)
(1) ε (eps, 입실론)
- 특정 데이터를 중심으로 하는 반경
- 이 반경 안에 다른 데이터가 몇 개 들어오는지를 기준으로 판단
(2) min_samples
- eps 반경 내에 포함되어야 할 최소 데이터 개수
- 이 개수를 만족하면 핵심 포인트가 됨
(3) 핵심 포인트 (Core Point)
- eps 반경 내에 min_samples 이상의 이웃을 가진 데이터
(4) 이웃 포인트 (Neighbor Point)
- eps 반경 안에 위치한 데이터
(5) 경계 포인트 (Border Point)
- min_samples는 만족하지 않지만
- 핵심 포인트의 이웃인 데이터
(6) 잡음 포인트 (Noise, -1)
- 어떤 핵심 포인트에도 속하지 않는 데이터
4. 붓꽃 데이터셋에 DBSCAN 적용
4-1. DBSCAN 모델 생성 및 군집화
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(
eps=0.6, # 입실론 반경
min_samples=8, # 핵심 포인트 기준
metric='euclidean' # 거리 계산 방식
)
# DBSCAN은 fit_predict로 바로 군집 레이블 반환
dbscan_labels = dbscan.fit_predict(iris.data)
# 결과를 DataFrame에 저장
irisDF['dbscan_cluster'] = dbscan_labels👉
- -1 값은 Noise(잡음 데이터) 를 의미합니다.
4-2. 실제 타깃과 DBSCAN 결과 비교
iris_result = irisDF.groupby(['target'])['dbscan_cluster'].value_counts()
print(iris_result)
target dbscan_cluster
0 0 49
-1 1
1 1 46
-1 4
2 1 42
-1 8👉
- Setosa는 거의 완벽
- Versicolor, Virginica는 일부 Noise 발생
- DBSCAN이 불확실한 샘플을 잡음으로 분리했음을 의미
5. PCA를 활용한 2차원 시각화
DBSCAN은 고차원에서 결과 해석이 어려우므로 PCA로 차원 축소 후 시각화합니다.
from sklearn.decomposition import PCA
# 2차원 PCA 변환
pca = PCA(n_components=2, random_state=0)
pca_transformed = pca.fit_transform(iris.data)
irisDF['ftr1'] = pca_transformed[:,0]
irisDF['ftr2'] = pca_transformed[:,1]
visualize_cluster_plot(
dbscan,
irisDF,
'dbscan_cluster',
iscenter=False # DBSCAN은 중심점 개념 없음
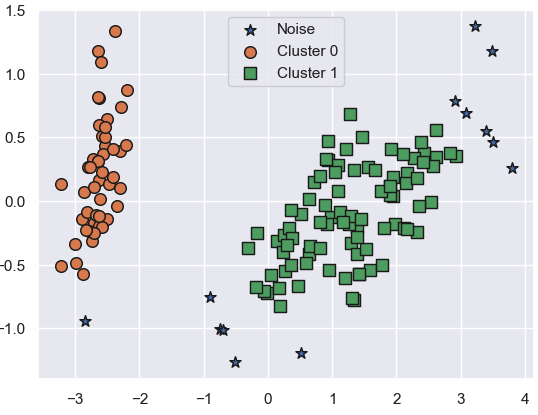
)👉
- DBSCAN은 중심점이 없으므로 iscenter=False
- Noise 포인트가 명확히 분리됨
6. eps 값 변화에 따른 영향
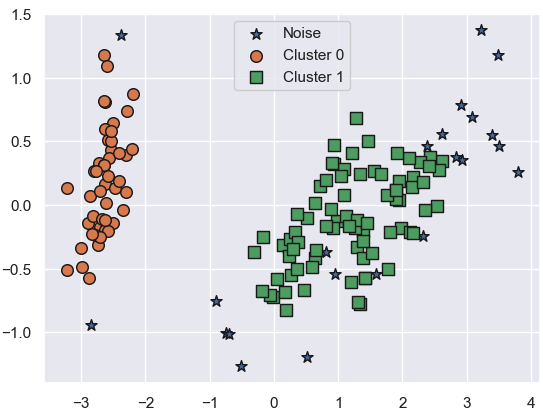
6-1. eps 증가 (0.8)
dbscan = DBSCAN(eps=0.8, min_samples=8, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
irisDF['dbscan_cluster'] = dbscan_labels👉
- eps 증가 → 더 많은 데이터가 군집에 포함
- Noise 감소, 군집 경계 완화

6-2. min_samples 증가 (16)
dbscan = DBSCAN(eps=0.6, min_samples=16, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
target dbscan_cluster
0 0 48
-1 2
1 1 44
-1 6
2 1 36
-1 14👉
- min_samples 증가 → 핵심 포인트 조건 강화
- Noise 급증
7. make_circles 데이터로 알고리즘 비교
7-1. 원형 데이터 생성
from sklearn.datasets import make_circles
X, y = make_circles(
n_samples=1000,
shuffle=True,
noise=0.05,
random_state=0,
factor=0.5
)
clusterDF = pd.DataFrame(X, columns=['ftr1', 'ftr2'])
clusterDF['target'] = y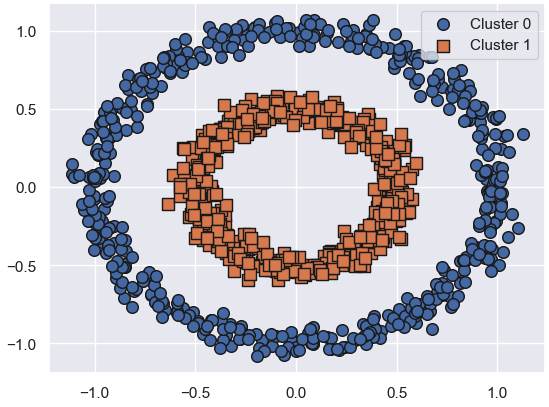
7-2. K-Means 적용 결과
kmeans = KMeans(n_clusters=2, max_iter=1000, random_state=0)
kmeans_labels = kmeans.fit_predict(X)
clusterDF['kmeans_cluster'] = kmeans_labels👉
- 원형 구조를 직선으로 잘라 잘못 분류

7-3. GMM 적용 결과
gmm = GaussianMixture(n_components=2, random_state=0)
gmm_label = gmm.fit(X).predict(X)
clusterDF['gmm_cluster'] = gmm_label👉
- 확률 기반이지만 여전히 원형 구조에는 한계
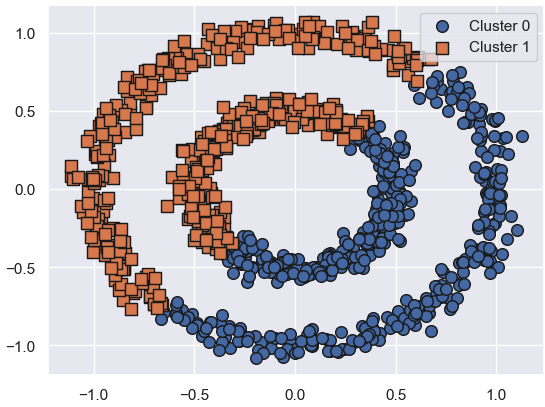
7-4. DBSCAN 적용 결과
dbscan = DBSCAN(eps=0.2, min_samples=10, metric='euclidean')
dbscan_labels = dbscan.fit_predict(X)
clusterDF['dbscan_cluster'] = dbscan_labels👉
- 완벽한 원형 군집 분리
- DBSCAN의 강점이 가장 잘 드러나는 사례

8. DBSCAN vs K-Means vs GMM 요약
| 알고리즘 | 군집개수 | 형태 | 이상치 |
| K-Means | 지정 필요 | 원형 | 취약 |
| GMM | 지정 필요 | 타원형 | 제한적 |
| DBSCAN | 자동 | 자유형 | 매우 강함 |
9. 결론
- DBSCAN은 밀도 기반 군집화 알고리즘
- 군집 개수를 모를 때 매우 강력
- 이상치 탐지에 탁월
- 복잡한 기하학 구조 데이터에 최적
👉 비정형·노이즈 데이터에서는 DBSCAN이 최우선 후보입니다.
반응형
'Programming' 카테고리의 다른 글
| 비지도학습(군집화) 마무리 정리: “정답이 없을 때, 무엇을 기준으로 묶을 것인가” (1) | 2026.01.12 |
|---|---|
| 고객 세그먼테이션 구현 실습RFM 기법 + K-Means 군집화 (0) | 2026.01.12 |
| Gaussian Mixture Model(GMM) 군집화– K-Means의 한계를 극복하는 확률 기반 군집 알고리즘 (0) | 2026.01.12 |
| Mean Shift 군집화 완전 이해– KDE 기반 자동 군집 개수 결정 알고리즘 (0) | 2026.01.12 |
| K-Means 군집 성능 평가를 위한 실루엣(Silhouette) 분석 완전 이해 (0) | 2026.01.12 |