
반응형

1. SVD 개요
SVD(Singular Value Decomposition, 특이값 분해)는 행렬을 구성 요소로 분해하는 선형대수 핵심 기법입니다.
차원 축소, 이미지 압축, 추천 시스템, 문서 의미 분석 등 머신러닝과 데이터 분석 전반에서 매우 중요한 역할을 합니다.
앞에서 배운 PCA, LDA 역시 내부적으로는 SVD 또는 고유값 분해를 기반으로 동작합니다.
2. PCA와 SVD의 관계 정리
- 고유값 분해(Eigen Decomposition)
→ 정방행렬(행 = 열)만 가능 - PCA
→ 공분산 행렬(정방행렬)에 고유값 분해 적용 - SVD
→ ✔️ 정방행렬 + 직사각형 행렬(m × n) 모두 가능
→ PCA보다 더 일반적인 행렬 분해 기법
즉,
PCA ⊂ SVD
라고 이해하면 됩니다.
3. SVD 수식적 의미 (입문자 관점)
임의의 행렬 A는 다음과 같이 분해됩니다.
A=UΣVT
| U | 왼쪽 특이 벡터 행렬 (직교) |
| Σ(Sigma) | 특이값 대각행렬 (중요도 크기) |
| Vᵀ | 오른쪽 특이 벡터 전치 행렬 (직교) |
- 특이 벡터(Singular Vector): 데이터의 주요 방향
- 특이값(Singular Value): 해당 방향의 중요도(에너지)
👉 특이값이 클수록 정보량이 큽니다.
4. Full SVD / Compact SVD / Truncated SVD
4.1 Full SVD
- 모든 특이값과 특이벡터 사용
- 계산량 많음
4.2 Compact SVD
- 0에 가까운 특이값 제거
- 메모리 절약
4.3 Truncated SVD
- 상위 K개의 특이값만 사용
- 차원 축소, 속도 개선에 핵심
- 대규모 데이터에 적합
5. NumPy를 이용한 SVD 실습7. 사이킷런
5.1 랜덤 행렬 생성
import numpy as np
from numpy.linalg import svd
# 재현성을 위해 시드 고정
np.random.seed(121)
# 4x4 랜덤 행렬 생성
a = np.random.randn(4,4)
print(np.round(a,3))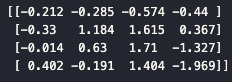
📌 의미
- 임의의 정방행렬을 생성하여 SVD 분해 과정을 직접 확인합니다.
5.2 Full SVD 수행
# SVD 수행
U, Sigma, Vt = svd(a)
print(U.shape, Sigma.shape, Vt.shape)
print('Sigma Value:\n', np.round(Sigma,3))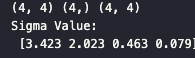
5.3 상위 2개 특이값만 사용한 복원 (Compact SVD)
# 상위 2개 성분만 사용
U_ = U[:, :2]
Sigma_ = np.diag(Sigma[:2])
Vt_ = Vt[:2]
print(U_.shape, Sigma_.shape, Vt_.shape)
# 행렬 복원
a_ = np.dot(np.dot(U_, Sigma_), Vt_)
print(np.round(a_, 3))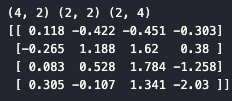
📌 목적
- 전체 정보를 사용하지 않고도 원본 행렬을 근사 복원할 수 있음을 확인합니다.
- 이미지 압축의 핵심 원리입니다
6. Truncated SVD 실습 (scipy)
from scipy.sparse.linalg import svds
from scipy.linalg import svd
np.random.seed(121)
matrix = np.random.random((6, 6))
print('원본 행렬:\n', matrix)
# Full SVD
U, Sigma, Vt = svd(matrix, full_matrices=False)
print('\n분해 행렬 차원:', U.shape, Sigma.shape, Vt.shape)
print('\nSigma값 행렬:', Sigma)
6.1 Truncated SVD 적용
num_components = 5
U_tr, Sigma_tr, Vt_tr = svds(matrix, k=num_components)
print('\nTruncated SVD 분해 행렬 차원:', U_tr.shape, Sigma_tr.shape, Vt_tr.shape)
print('\nTruncated SVD Sigma값 행렬:', Sigma_tr)
# Truncated SVD로 행렬 복원
matrix_tr = np.dot(np.dot(U_tr, np.diag(Sigma_tr)), Vt_tr)
print('\nTruncated SVD로 분해 후 복원 행렬:\n', matrix_tr)📌 의미
- 상위 특이값만 사용해도 원본 구조를 상당 부분 유지합니다.
- 대규모 희소 행렬 처리에 매우 효과적입니다.
7. TruncatedSVD 실습 (Iris 데이터)
from sklearn.decomposition import TruncatedSVD, PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
%matplotlib inline
iris = load_iris()
iris_ftrs = iris.data
# TruncatedSVD 적용
tsvd = TruncatedSVD(n_components=2)
tsvd.fit(iris_ftrs)
iris_tsvd = tsvd.transform(iris_ftrs)
plt.scatter(x=iris_tsvd[:,0], y=iris_tsvd[:,1], c=iris.target)
plt.xlabel('TruncatedSVD Component 1')
plt.ylabel('TruncatedSVD Component 2')
7.1 PCA와 Truncated SVD 비교
from sklearn.preprocessing import StandardScaler
# 스케일링
scaler = StandardScaler()
iris_scaled = scaler.fit_transform(iris_ftrs)
# Truncated SVD
tsvd = TruncatedSVD(n_components=2)
iris_tsvd = tsvd.fit_transform(iris_scaled)
# PCA
pca = PCA(n_components=2)
iris_pca = pca.fit_transform(iris_scaled)
# 시각화
fig, (ax1, ax2) = plt.subplots(figsize=(9,4), ncols=2)
ax1.scatter(x=iris_tsvd[:,0], y=iris_tsvd[:,1], c=iris.target)
ax2.scatter(x=iris_pca[:,0], y=iris_pca[:,1], c=iris.target)
ax1.set_title('Truncated SVD Transformed')
ax2.set_title('PCA Transformed')
8. NMF (Non-negative Matrix Factorization)
from sklearn.decomposition import NMF
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
%matplotlib inline
iris = load_iris()
iris_ftrs = iris.data
# NMF 적용
nmf = NMF(n_components=2)
nmf.fit(iris_ftrs)
iris_nmf = nmf.transform(iris_ftrs)
plt.scatter(x=iris_nmf[:,0], y=iris_nmf[:,1], c=iris.target)
plt.xlabel('NMF Component 1')
plt.ylabel('NMF Component 2')
📌 NMF 특징
- 입력 데이터와 결과가 모두 음수가 아님
- 해석력이 뛰어나 문서 토픽 모델링에 자주 사용
9. SVD 활용 사례 정리
- 이미지 압축
- 추천 엔진(잠재 요인 분해)
- 문서 잠재 의미 분석(LSA)
- 차원 축소
- 의사역행렬(Pseudo-inverse)
- 희소 행렬 처리
10. 핵심 요약
- SVD는 가장 범용적인 행렬 분해 기법
- PCA, LDA, NMF 등 다수 기법의 기반
- Truncated SVD는 대규모 데이터에서 필수
- 특이값 = 정보량, 특이벡터 = 방향
반응형
'Programming' 카테고리의 다른 글
| 군집화(Clustering) 개념과 K-Means 알고리즘 실습 정리 (0) | 2026.01.12 |
|---|---|
| 차원 축소(Dimension Reduction) 완전 정리 요약PCA · LDA · SVD · Truncated SVD · NMF (0) | 2026.01.11 |
| LDA(Linear Discriminant Analysis) – 분류를 위한 차원 축소 기법 (1) | 2026.01.11 |
| 신용카드 데이터 세트 PCA 변환과 분류 성능 비교 (1) | 2026.01.11 |
| 차원 축소(Dimension Reduction) 이해와 PCA 실습 (0) | 2026.01.11 |