
반응형
1. 개요
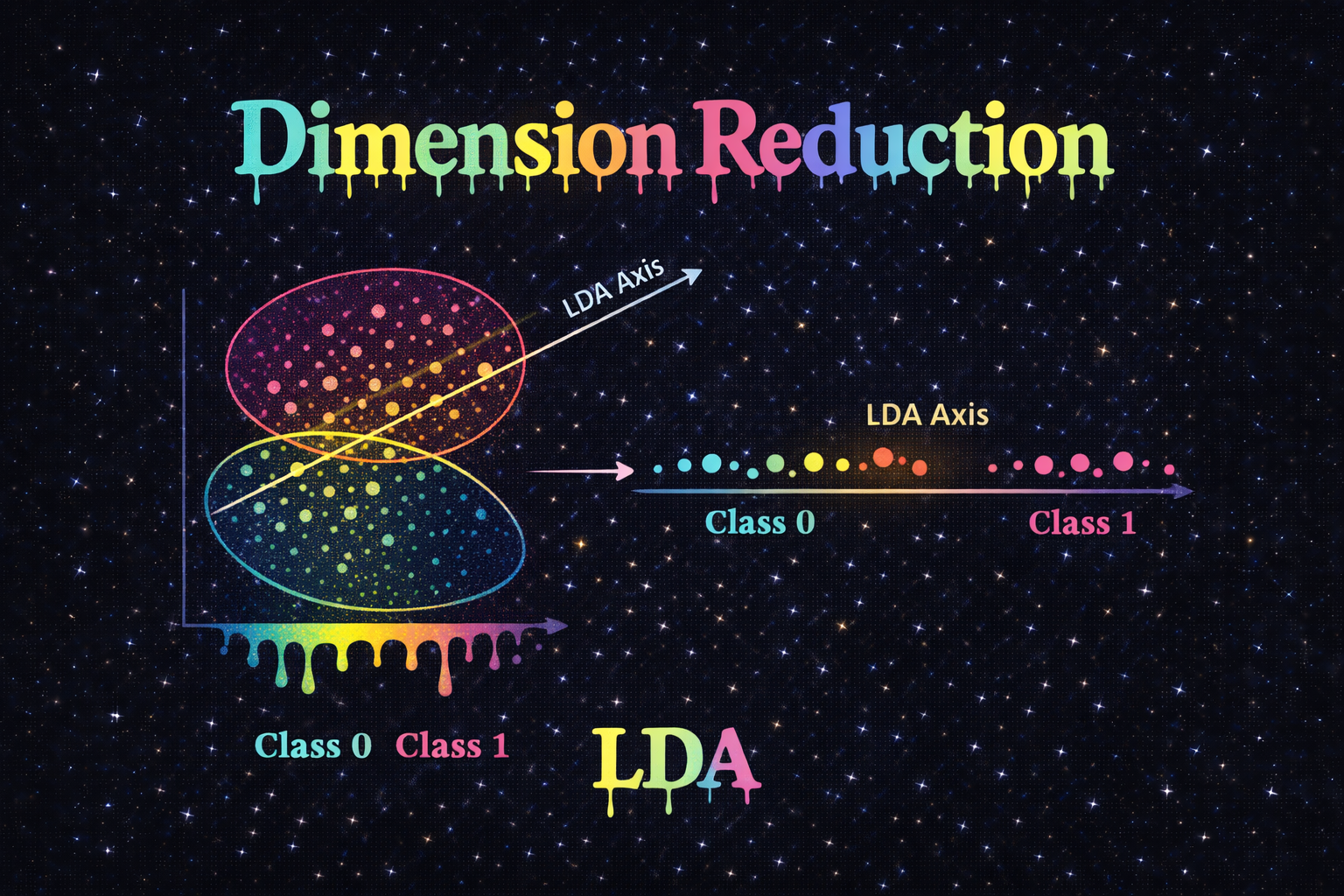
LDA(Linear Discriminant Analysis, 선형 판별 분석)는 분류 문제에 특화된 차원 축소 기법입니다.
겉보기에는 PCA와 매우 유사하지만, 차원 축소의 기준 자체가 다르다는 점이 핵심 차이입니다.
- PCA: 데이터의 분산(변동성) 이 가장 큰 방향을 기준으로 차원 축소
- LDA: 클래스 간 구분이 가장 잘 되도록 차원 축소
즉,
👉 PCA는 비지도 학습 기반 차원 축소,
👉 LDA는 지도 학습 기반 차원 축소라고 이해하면 됩니다.
2. PCA와 LDA의 핵심 차이
| 구분 | PCA | LDA |
| 학습 방식 | 비지도 학습 | 지도 학습 |
| 기준 | 데이터 분산 최대화 | 클래스 분리 최대화 |
| 타깃 사용 여부 | 사용 안 함 | 사용함 |
| 목적 | 정보 손실 최소화 | 분류 성능 향상 |
LDA는 클래스 정보를 적극적으로 사용하여
- 같은 클래스 데이터는 서로 가깝게
- 다른 클래스 데이터는 서로 멀어지도록
축(axis)을 찾습니다.
3. LDA의 수학적 직관 (입문자 관점)
LDA는 다음 비율을 최대화하는 축을 찾습니다.
의미를 쉽게 풀면
- 클래스 간 분산: 서로 다른 클래스 중심들이 얼마나 떨어져 있는가
- 클래스 내 분산: 같은 클래스 내부 데이터가 얼마나 퍼져 있는가
👉 목표는
- 클래스 중심 간 거리는 최대한 크게
- 클래스 내부 퍼짐은 최대한 작게
이 기준을 만족하는 방향으로 데이터를 투영합니다.
4. Iris 데이터로 LDA 실습
4.1 데이터 로딩 및 표준화
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 사이킷런에서 Iris 데이터 로딩
iris = load_iris()
# LDA 역시 거리/분산 기반 기법이므로
# 평균 0, 분산 1로 표준화 수행
iris_scaled = StandardScaler().fit_transform(iris.data)📌 왜 StandardScaler를 사용할까?
- 피처 단위(scale)가 다르면 특정 피처가 LDA 방향을 지배할 수 있기 때문입니다.
4.2 LDA 모델 생성 및 변환
# LDA 객체 생성
# n_components=2 : 2차원으로 차원 축소
# (분류 클래스 개수 - 1 이하만 가능)
lda = LinearDiscriminantAnalysis(n_components=2)
# 입력 데이터 + 타깃을 함께 학습
# 👉 PCA와 가장 큰 차이점
lda.fit(iris_scaled, iris.target)
# 학습된 LDA 축 기준으로 데이터 변환
iris_lda = lda.transform(iris_scaled)
print(iris_lda.shape)📌 중요 포인트
- Iris 데이터는 클래스가 3개이므로
→ LDA 최대 차원 수는 3 - 1 = 2 - 따라서 n_components=2가 최대입니다.
5. LDA 결과 시각화
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# LDA 결과를 DataFrame으로 변환
lda_columns = ['lda_component_1', 'lda_component_2']
irisDF_lda = pd.DataFrame(iris_lda, columns=lda_columns)
# 타겟 컬럼 추가
irisDF_lda['target'] = iris.target5.1 클래스별 산점도 시각화
# setosa: 세모, versicolor: 네모, virginica: 동그라미
markers = ['^', 's', 'o']
for i, marker in enumerate(markers):
# 각 클래스에 해당하는 데이터만 추출
x_axis_data = irisDF_lda[irisDF_lda['target'] == i]['lda_component_1']
y_axis_data = irisDF_lda[irisDF_lda['target'] == i]['lda_component_2']
# 클래스별 산점도 출력
plt.scatter(
x_axis_data,
y_axis_data,
marker=marker,
label=iris.target_names[i]
)
plt.legend(loc='upper right')
plt.xlabel('lda_component_1')
plt.ylabel('lda_component_2')
plt.show()
6. 시각화 결과 해석
- PCA 대비 클래스 간 분리가 훨씬 명확합니다.
- 특히 versicolor와 virginica가
PCA에서는 일부 섞였던 반면,
LDA에서는 결정 경계가 더 뚜렷하게 나타납니다.
👉 이는 LDA가 분류를 목표로 축을 찾았기 때문입니다.
7. PCA vs LDA 언제 사용할까?
PCA가 적합한 경우
- 타깃이 없는 경우
- 데이터 탐색, 시각화 목적
- 노이즈 제거, 차원 압축 목적
LDA가 적합한 경우
- 분류 문제
- 클래스 라벨이 존재
- 분류 성능 개선이 목적
8. 정리
- LDA는 차원 축소 + 분류 성능 향상을 동시에 노리는 기법입니다.
- PCA와 달리 클래스 정보를 적극적으로 활용합니다.
- 클래스 개수가 K라면, LDA의 최대 차원은 K-1입니다.
- 분류 문제에서 PCA보다 LDA가 더 좋은 선택이 되는 경우가 많습니다.
반응형
'Programming' 카테고리의 다른 글
| 차원 축소(Dimension Reduction) 완전 정리 요약PCA · LDA · SVD · Truncated SVD · NMF (0) | 2026.01.11 |
|---|---|
| SVD(Singular Value Decomposition, 특이값 분해) 이해하기 (0) | 2026.01.11 |
| 신용카드 데이터 세트 PCA 변환과 분류 성능 비교 (1) | 2026.01.11 |
| 차원 축소(Dimension Reduction) 이해와 PCA 실습 (0) | 2026.01.11 |
| 회귀(Regression) 핵심 개념 최종 요약 정리 (0) | 2026.01.09 |