
반응형

1. 개요
신용카드 데이터는 피처 수가 많고, 피처 간 상관관계가 높은 대표적인 데이터입니다.
특히 결제 금액(BILL_AMT) 계열 변수들은 시간 순서에 따라 강한 상관성을 가지므로, 그대로 모델에 투입할 경우 다중 공선성 문제와 과적합 가능성이 커집니다.
이 글에서는
- 신용카드 데이터의 상관관계 분석
- 상관도가 높은 피처에 대한 PCA 적용
- PCA 변환 전·후 분류 성능 비교
- PCA 결과(변동성 비율)의 의미 해석
을 입문자도 이해할 수 있도록 단계별로 설명합니다.
2. 데이터 로딩 및 기본 전처리
import pandas as pd
# pandas에서 컬럼을 최대 30개까지 출력하도록 설정
# (피처가 많은 데이터의 구조를 한눈에 보기 위함)
pd.set_option('display.max_columns', 30)
# 엑셀 파일 로딩
# header=1 : 실제 컬럼명이 2번째 행에 위치
# sheet_name='Data' : Data 시트 선택
# iloc[:, 1:] : 첫 번째 컬럼(ID 컬럼) 제거
df = pd.read_excel(
'./creditCard/pca_credit_card.xls',
header=1,
sheet_name='Data',
engine='xlrd'
).iloc[:, 1:]
# 데이터 크기 확인
print(df.shape)
# 상위 3개 행 확인
df.head(3)📌 목적 설명
- 신용카드 데이터는 ID 컬럼이 예측에 의미가 없으므로 제거합니다.
- 데이터 전체 구조와 피처 개수를 먼저 파악하는 것이 중요합니다.

3. 컬럼명 정리 및 타깃/피처 분리
# 컬럼명 일부를 이해하기 쉽게 변경
df.rename(
columns={
'PAY_0': 'PAY_1',
'default payment next month': 'default'
},
inplace=True
)
# 타깃 변수: 다음 달 연체 여부
y_target = df['default']
# 입력 피처: 타깃을 제외한 모든 컬럼
X_features = df.drop('default',
axis=1)📌 목적 설명
- 컬럼명을 일관성 있게 정리하면 이후 분석과 코드 가독성이 좋아집니다.
- 지도학습에서는 반드시 타깃(y)과 피처(X)를 명확히 분리해야 합니다.
4. 피처 간 상관관계 분석
# 피처 간 상관계수 계산
corr = X_features.corr()
corr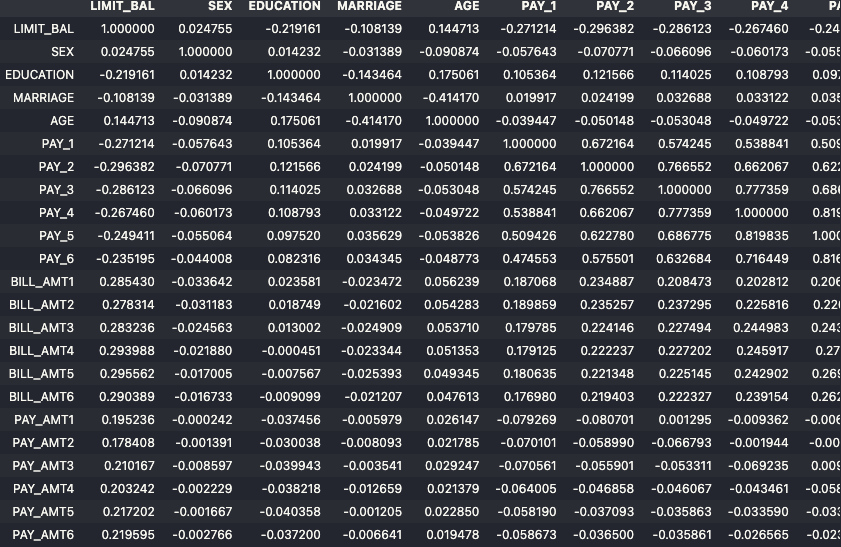
📌 의미
- 상관계수가 1에 가까울수록 두 피처는 거의 같은 정보를 담고 있습니다.
- 상관도가 높은 피처가 많으면 차원 축소 또는 피처 선택이 필요합니다.
5. 상관관계 히트맵 시각화
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(14,14))
# 상관계수 히트맵 시각화
sns.heatmap(
corr,
annot=True, # 상관계수 값 표시
fmt='.1g' # 소수점 간소화
)
plt.show()
📌 해석 포인트
- BILL_AMT1 ~ BILL_AMT6 사이에 매우 강한 양의 상관관계가 존재합니다.
- 이는 시간에 따른 카드 사용 금액이 서로 유사하게 움직이기 때문입니다.
6. BILL_AMT 계열에 PCA 적용
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# BILL_AMT1 ~ BILL_AMT6 컬럼 리스트 생성
cols_bill = ['BILL_AMT' + str(i) for i in range(1, 7)]
print(f'컬럼명 : {cols_bill}')📌 왜 이 피처들만 PCA를 적용할까?
- 이 피처들은 서로 매우 강한 상관관계를 가지므로
- PCA를 통해 중복 정보를 압축하는 것이 합리적입니다.
(1) 표준화 수행
# PCA는 분산 기반 기법이므로 반드시 표준화 필요
scaler = StandardScaler()
# BILL_AMT 계열 피처만 표준화
df_cols_scaled = scaler.fit_transform(X_features[cols_bill])📌 이유
- 스케일이 큰 피처가 PCA 결과를 지배하는 것을 방지합니다.
(2) PCA 변환 수행
# 2개의 주성분으로 차원 축소
pca = PCA(n_components=2)
# PCA 학습
pca.fit(df_cols_scaled)
# 각 PCA 컴포넌트가 설명하는 변동성 비율 출력
print(f'PCA Component 별 변동성 : {pca.explained_variance_ratio_}')
[0.90555253 0.0509867 ]✅ 결과 해석 (중요)
- 첫 번째 PCA 컴포넌트가 전체 분산의 약 90.6% 설명
- 두 번째 PCA 컴포넌트는 약 **5.1%**만 설명
👉 즉,
BILL_AMT1~6의 정보 대부분은 하나의 축으로 거의 요약 가능하다는 의미입니다.
이는 강한 다중 공선성이 존재함을 수치적으로 증명합니다.
7. PCA 적용 전 분류 성능 평가
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 랜덤 포레스트 분류기 생성
rcf = RandomForestClassifier(
n_estimators=300,
random_state = 156
)
# 원본 피처로 교차 검증 수행
scores = cross_val_score(
rcf,
X_features,
y_target,
scoring='accuracy',
cv=3
)
print(f'CV=3 개별 fold 정확도 : {scores}')
print(f'CV=3 평균 정확도 : {np.mean(scores)}')📌 결과
- 평균 정확도 약 0.818
- 차원은 크지만 정보 손실은 없음
8. 전체 피처에 PCA 적용 후 성능 비교
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 전체 피처에 대해 표준화 수행
scaler = StandardScaler()
df_scaled = scaler.fit_transform(X_features)
# 6개의 PCA 컴포넌트 생성
pca = PCA(n_components=6)
df_pca = pca.fit_transform(df_scaled)
# PCA 변환 데이터로 교차 검증 수행
scores_pca = cross_val_score(
rcf,
df_pca,
y_target,
scoring='accuracy',
cv=3
)
print(f'CV=3 PCA 개별 fold 정확도 : {scores_pca}')
print(f'CV=3 PCA 평균 정확도 : {np.mean(scores_pca)}')📌 결과
- PCA 적용 후 평균 정확도 약 0.797
- 성능은 다소 감소했으나
- 차원 축소
- 노이즈 감소
- 모델 단순화
효과를 함께 얻을 수 있음
9. 결론
- 신용카드 데이터는 상관도가 높은 피처가 매우 많은 데이터입니다.
- PCA는 이러한 중복 정보를 소수의 잠재적 축으로 압축하는 데 매우 효과적입니다.
- 분류 성능이 약간 감소하더라도
- 계산 비용 감소
- 과적합 완화
- 모델 안정성 향상
이라는 실무적 이점을 제공합니다.
- 특히 BILL_AMT 계열처럼 시계열적으로 유사한 피처 그룹에는 PCA가 매우 적합합니다.
반응형
'Programming' 카테고리의 다른 글
| SVD(Singular Value Decomposition, 특이값 분해) 이해하기 (0) | 2026.01.11 |
|---|---|
| LDA(Linear Discriminant Analysis) – 분류를 위한 차원 축소 기법 (1) | 2026.01.11 |
| 차원 축소(Dimension Reduction) 이해와 PCA 실습 (0) | 2026.01.11 |
| 회귀(Regression) 핵심 개념 최종 요약 정리 (0) | 2026.01.09 |
| 캐글 주택가격 예측 : 고급 회귀 기법 (3편) : 회귀 트리 모델 · 예측 혼합 · 스태킹(Stacking) 앙상블 (0) | 2026.01.09 |