
반응형

1. 5-Fold 교차 검증으로 모델 일반화 성능 확인
1편에서는 단일 train/test split 기준 성능을 확인했습니다.
하지만 이는 데이터 분할에 따라 결과가 흔들릴 수 있습니다.
따라서 교차 검증(Cross Validation) 을 통해 모델의 일반화 성능을 평가합니다.
from sklearn.model_selection import cross_val_score
def get_avg_rmse_cv(models):
"""
여러 회귀 모델에 대해
5-Fold 교차 검증 기반 RMSE 리스트와 평균 RMSE를 출력하는 함수
목적:
- 특정 데이터 분할에 의존하지 않고
- 모델의 '일반화 성능'을 안정적으로 평가하기 위함
"""
for model in models:
# cross_val_score는 기본적으로 '점수가 클수록 좋은 값'을 기준으로 함
# RMSE는 작을수록 좋기 때문에 neg_mean_squared_error 사용
rmse_list = np.sqrt(-cross_val_score(
model,
X_features,
y_target,
scoring='neg_mean_squared_error',
cv=5
))
# 5개 fold에서 계산된 RMSE의 평균
rmse_avg = np.mean(rmse_list)
print(f'CV RMSE 값 리스트 : {model.__class__.__name__} - {np.round(rmse_list, 3)}')
print(f'CV 평균 RMSE 값 : {model.__class__.__name__} - {np.round(rmse_avg,3)}')
models = [ridge_reg, lasso_reg]
get_avg_rmse_cv(models)
CV RMSE 값 리스트 : Ridge - [0.12 0.156 0.141 0.13 0.192]
CV 평균 RMSE 값 : Ridge - 0.148
CV RMSE 값 리스트 : Lasso - [0.161 0.204 0.177 0.182 0.265]
CV 평균 RMSE 값 : Lasso - 0.198해석
- Ridge가 Lasso보다 일관되게 낮은 RMSE
- Lasso는 fold에 따라 성능 변동이 큼
→ 계수 축소가 과도해 불안정
2. GridSearchCV를 이용한 alpha 튜닝
규제 회귀의 성능은 alpha 값에 절대적으로 의존합니다.
따라서 GridSearchCV로 최적 alpha 탐색을 수행합니다.
from sklearn.model_selection import GridSearchCV
def print_best_params(model, params):
"""
GridSearchCV를 이용해
alpha 값에 따른 최적 RMSE와 최적 모델을 반환하는 함수
목적:
- 규제 강도(alpha)를 체계적으로 탐색
- 사람이 감으로 튜닝하는 것을 방지
"""
grid_model = GridSearchCV(
model,
param_grid=params,
scoring='neg_mean_squared_error',
cv=5
)
grid_model.fit(X_features, y_target)
# best_score_는 음수 MSE → 다시 양수 RMSE로 변환
rmse = np.sqrt(-1 * grid_model.best_score_)
print(f'5 폴드시 최적 평균 RMSE : {np.round(rmse,4)}')
print(f'최적 alpha : {grid_model.best_params_}')
return grid_model.best_estimator_
ridge_params = {'alpha':[0.05,0.1,1,5,8,10,12,15,20]}
lasso_params = {'alpha':[0.001,0.005,0.008,0.05,0.03,0.1,0.5,1.5,10]}
best_rige = print_best_params(ridge_reg, ridge_params)
bset_lasso = print_best_params(lasso_reg, lasso_params)
# 5 폴드시 최적 평균 RMSE : 0.1397
# 최적 alpha : {'alpha': 15}
# 5 폴드시 최적 평균 RMSE : 0.1404
# 최적 alpha : {'alpha': 0.001}해석
- Ridge: alpha=15
- Lasso: alpha=0.001
→ Lasso는 매우 약한 규제에서만 성능 유지
3. 최적 alpha로 재학습 및 성능 비교
from sklearn.linear_model import LinearRegression
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge(alpha=12)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)
로그 변환 RMSE : LinearRegression - 0.166
로그 변환 RMSE : Ridge - 0.122
로그 변환 RMSE : Lasso - 0.119결과 요약
- Ridge / Lasso 성능 모두 1편 대비 개선
- 특히 Lasso 계수가 안정화됨
models = [lr_reg, ridge_reg, lasso_reg]
visualize_coefficient(models)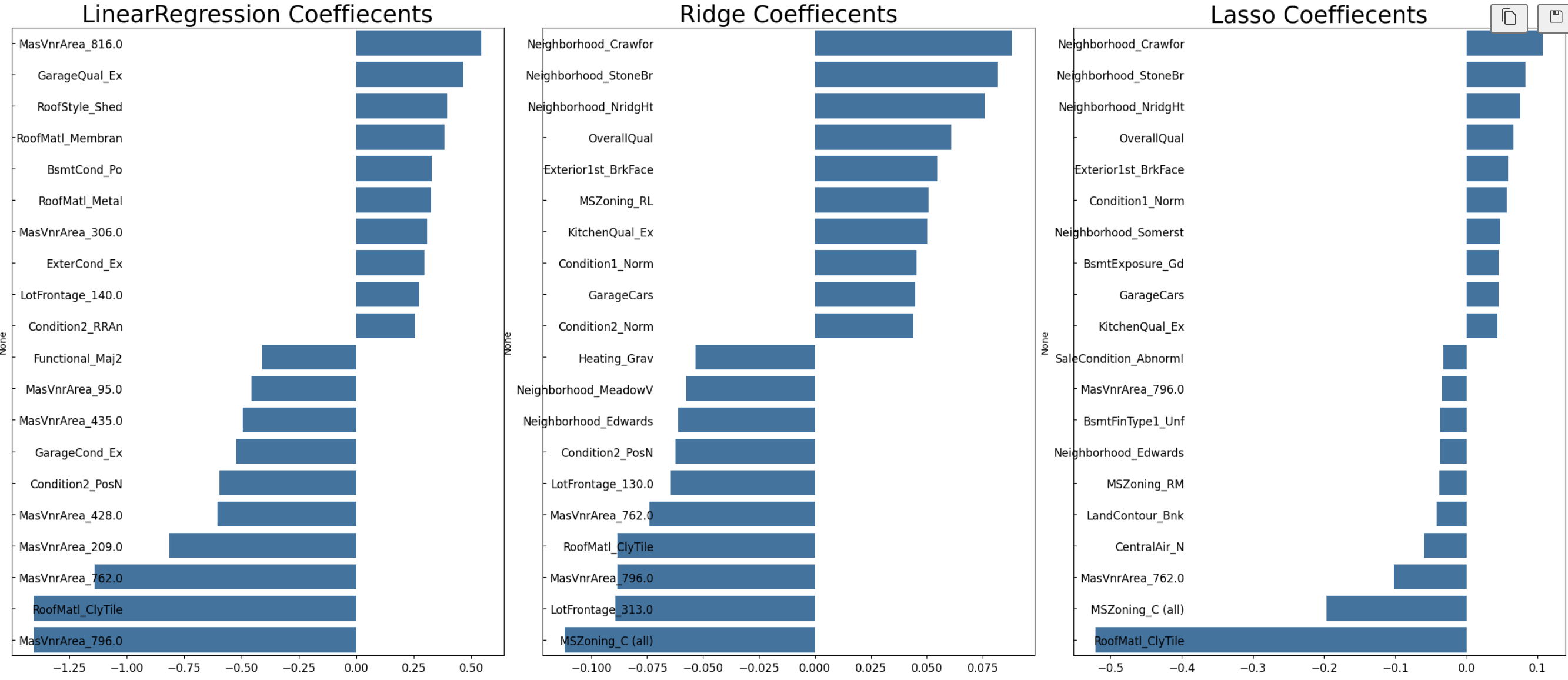
해석
- Lasso 회귀계수가 0에 몰리는 현상 완화
- 의미 있는 피처들이 다시 살아남음
4. 숫자 피처 왜도(Skewness) 분석
선형 모델은 정규분포에 가까운 피처를 선호합니다.
따라서 왜도(Skewness) 가 큰 피처를 찾아 추가 로그 변환을 수행합니다.
from scipy.stats import skew
# object 타입이 아닌 숫자형 피처만 선택
features_index = house_df.dtypes[house_df.dtypes != 'object'].index
# 각 피처의 왜도 계산
skew_features = house_df[features_index].apply(lambda x : skew(x))
# 왜도가 1보다 큰(right skew) 피처만 추출
skew_features_top = skew_features[skew_features > 1]
print(skew_features_top.sort_values(ascending=False))
핵심 개념 정리
- Skewness ∈ [-0.5, 0.5] → 거의 대칭
- Skewness > 1 → 심한 right skew
- 실무 데이터는 대부분 right skew
5. 숫자 피처 왜도(Skewness) 분석
house_df[skew_features_top.index] = np.log1p(house_df[skew_features_top.index])주의 사항
- 음수 값이 있으면 로그 변환 불가
- 변환 기준은 학습 데이터 기준
- 테스트 데이터에도 동일한 변환 필수
6. 다시 원-핫 인코딩 및 재학습
house_df_ohe = pd.get_dummies(house_df)
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice', axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(
X_features,
y_target,
test_size=0.2,
random_state=156
)
best_rige = print_best_params(ridge_reg, ridge_params)
bset_lasso = print_best_params(lasso_reg, lasso_params)
5 폴드시 최적 평균 RMSE : 0.1273
최적 alpha : {'alpha': 15}
5 폴드시 최적 평균 RMSE : 0.1252
최적 alpha : {'alpha': 0.001}결과
- RMSE가 다시 유의미하게 감소
- 로그 변환 + 규제 회귀의 시너지 확인
7. 이상치(outlier) 탐색 및 제거
plt.scatter(
x=house_df_org['GrLivArea'],
y=house_df_org['SalePrice']
)
plt.xlabel('GrLivArea')
plt.ylabel('SalePrice')
plt.show()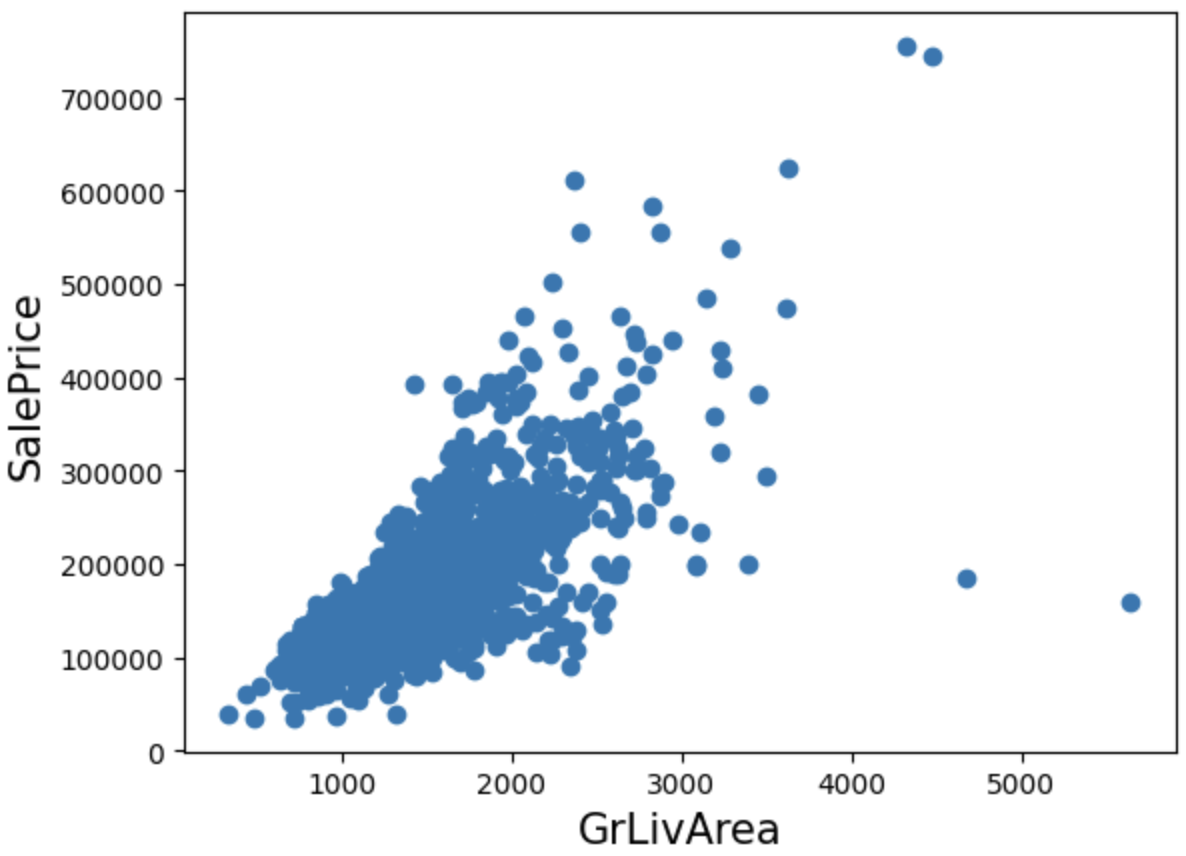
해석
- 면적은 매우 큰데 가격이 비정상적으로 낮은 데이터 존재
- 선형 회귀에서 심각한 성능 저하 원인
# GrLivArea와 SalePrice 모두 로그 변환 기준으로 조건 설정
cond1 = house_df_ohe['GrLivArea'] > np.log1p(4000)
cond2 = house_df_ohe['SalePrice'] < np.log1p(500000)
outlier_index = house_df_ohe[cond1 & cond2].index
print('아웃라이어 레코드 index :', outlier_index.values)
print('아웃라이어 삭제 전 house_df_ohe shape:', house_df_ohe.shape)
house_df_ohe.drop(outlier_index , axis=0, inplace=True)
print('아웃라이어 삭제 후 house_df_ohe shape:', house_df_ohe.shape)
8. 이상치 제거 후 최종 성능 평가
ridge_params = { 'alpha':[0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha':[0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1,5, 10] }
best_ridge = print_best_params(ridge_reg, ridge_params)
best_lasso = print_best_params(lasso_reg, lasso_params)
# 5 폴드시 최적 평균 RMSE : 0.1126
# 최적 alpha : {'alpha': 10}
# 5 폴드시 최적 평균 RMSE : 0.1122
# 최적 alpha : {'alpha': 0.001}
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge(alpha=10)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
# 로그 변환 RMSE : LinearRegression - 0.172
# 로그 변환 RMSE : Ridge - 0.103
# 로그 변환 RMSE : Lasso - 0.1
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)
visualize_coefficient(models)
최종 결과
- Ridge RMSE ≈ 0.103
- Lasso RMSE ≈ 0.100
- 1편 대비 압도적인 성능 개선
✅ 2편 핵심 요약
- 교차 검증은 필수
- alpha 튜닝은 성능의 핵심
- 왜도 보정 + 이상치 제거는 선형 모델 성능을 결정
- 이제 선형 모델의 한계에 도달
반응형
'Programming' 카테고리의 다른 글
| 회귀(Regression) 핵심 개념 최종 요약 정리 (0) | 2026.01.09 |
|---|---|
| 캐글 주택가격 예측 : 고급 회귀 기법 (3편) : 회귀 트리 모델 · 예측 혼합 · 스태킹(Stacking) 앙상블 (0) | 2026.01.09 |
| 캐글 주택가격 예측 프로젝트 (1편) : 고급 회귀 기법을 위한 데이터 이해와 선형 회귀 모델 분석 (0) | 2026.01.09 |
| Bike Demand 예측 프로젝트 : 회귀 기반 수요 예측 실전 프로젝트 정리 (0) | 2026.01.09 |
| 로지스틱 회귀와 회귀 트리 기반 모델 이해 (0) | 2026.01.05 |