
반응형

1. 프로젝트 개요
Bike Demand 데이터셋은 시간·날씨·계절 정보를 기반으로
자전거 대여 수요(count) 를 예측하는 전형적인 회귀(Regression) 문제입니다.
이 프로젝트의 목표는 다음과 같습니다.
- 데이터 특성을 이해하고 적절한 전처리 전략을 적용
- RMSLE / RMSE / MAE 등 회귀 평가 지표를 정확히 이해
- 선형 회귀 → 규제 회귀 → 트리 기반 앙상블 모델까지 단계적으로 성능 개선
- 실제 캐글(Kaggle) Bike Demand 문제 접근 방식 체득
2. 데이터 로드 및 기본 확인
bike_df = pd.read_csv('./bike/train.csv')
print(bike_df.shape)
display(bike_df.head(3))- 데이터 크기: 10,886 rows × 12 columns
- 타겟 변수: count (자전거 대여 횟수)
주요 컬럼 설명
- datetime : 날짜 + 시간
- season : 계절 (1~4)
- holiday : 공휴일 여부
- workingday : 근무일 여부
- weather : 날씨 상태
- temp, atemp : 온도 / 체감온도
- humidity, windspeed
- casual, registered : 사용자 유형별 대여 수
- count : 예측 대상
3. 날짜 데이터 처리 (Feature Engineering)
머신러닝 모델은 문자열 형태의 날짜를 직접 이해하지 못하므로
datetime → 수치형 피처 분해가 필요합니다.
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x : x.hour)
#불필요 컬럼 제거
drop_columns = ['datetime','casual','registered']
bike_df.drop(drop_columns, axis=1, inplace=True)casual, registered는 count를 직접 구성 → 데이터 누수(Data Leakage) 방지
4. 범주형 피처와 수요의 관계 시각화
fig, axs = plt.subplots(
figsize=(16,8),
ncols=4,
nrows=2
)
cat_features = ['year','month','season','weather', 'day', 'hour','holiday','workingday']
#위 리스트에 있는 컬럼별 합을 barplot으로 그림
for i, feature in enumerate(cat_features):
row = int(i/4)
col = i%4
#시본의 barplot을 이용해 컬럼값에 따른 count 평균값 표현
sns.barplot(x=feature,
y='count',
data=bike_df,
ax=axs[row][col])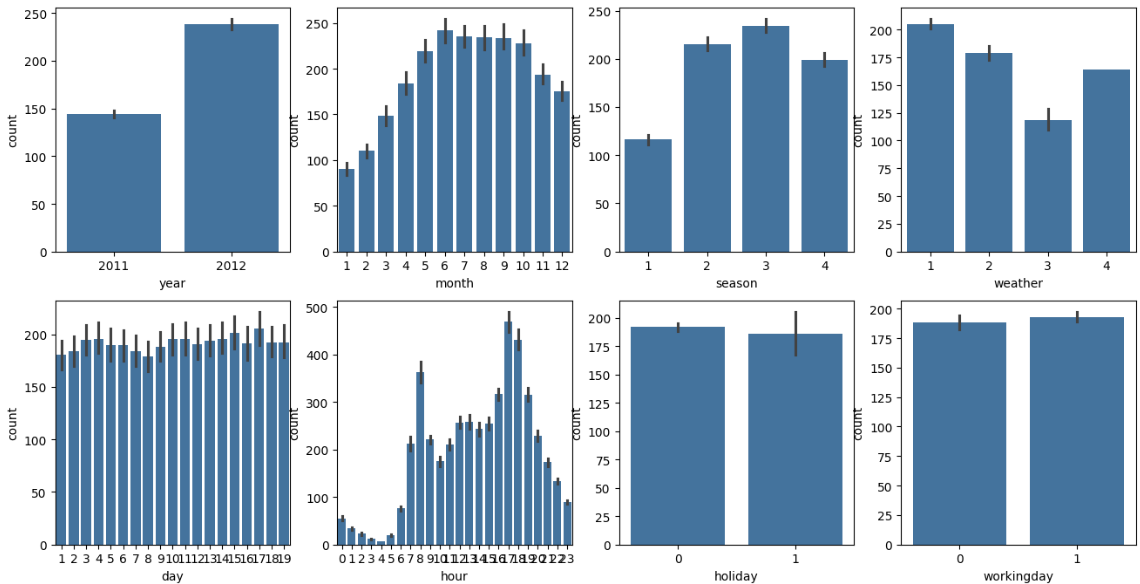
5. 회귀 평가 지표 정의
왜 RMSLE가 중요한가?
- Bike Demand는 수요 예측
- 실제 값이 큰 경우 오차도 자연히 커짐
- RMSLE는 상대적 오차를 완화해 줌
from sklearn.metrics import mean_squared_error, mean_absolute_error
#log 변환시 NaN등의 이슈로 log() 가 아닌 log1p()를 이용하여 RMSLE 계산
def rmsle(y, pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y-log_pred)**2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle
#사이킷런의 mean_square_error()를 이용하여 RMSE 계산
def rmse(y,pred):
return np.sqrt(mean_squared_error(y, pred))
#MSE, RMSE, RMSLE 모두 계산
def evaluate_regr(y,pred):
rmsle_val = rmsle(y,pred)
rmse_val = rmse(y,pred)
#MSE > sickit learn 의 mean_absolute_error()로 계산
mae_val = mean_absolute_error(y,pred)
print(f'RMSLE : {rmsle_val}\nRMSE : {rmse_val}\nMAE : {mae_val}')log1p / expm1 사용하는 이유
- log(0) → -inf 오류 발생
- log1p(x) = log(x+1) → 안전한 로그 변환
- expm1(x) → 원래 스케일 복원
6. 기본 선형 회귀 모델 (Baseline)
lr_reg = LinearRegression()
lr_reg.fit(X_train,y_train)
pred = lr_reg.predict(X_test)
evaluate_regr(y_test, pred)결과 해석
- RMSLE ≈ 1.16
- 큰 오차 발생 → 과소적합(Underfitting)
get_top_error_data(y_test, pred)- 실제 수요가 매우 큰 구간에서 예측 실패
7. 타겟값 로그 변환 (핵심 개선 포인트)
y_target_log = np.log1p(y_target)
- 수요 데이터는 오른쪽으로 긴 분포(skewed)
- 로그 변환 → 분포 안정화
pred_exp = np.expm1(pred)
- 평가 전 반드시 원래 스케일로 복원
➡ RMSLE 개선 확인
8. One-Hot Encoding 적용
연, 월, 시(hour) 등은 수치형이지만 실제로는 범주형
X_features_ohe = pd.get_dummies(
X_features,
columns=['year','month','day','hour','holiday','workingday','season','weather']
)9. 선형 / 규제 회귀 비교
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha=0.01)결과 요약
| 모델 | RMSLE |
| Linear | 0.589 |
| Ridge | 0.590 |
| Lasso | 0.634 |
10. 트리 기반 앙상블 모델 적용
rf_reg = RandomForestRegressor(n_estimators=500)
gbm_reg = GradientBoostingRegressor(n_estimators=500)
xgb_reg = XGBRegressor(n_estimators=500)
lgbm_reg = LGBMRegressor(n_estimators=500)| 모델 | RMSLE |
| Linear | 0.589 |
| Ridge | 0.590 |
| Lasso | 0.634 |
| LightGBM | 0.318 ✅ |
11. 프로젝트 결론
- Bike Demand는 비선형 + 시간 패턴이 강한 문제
- 단순 선형 회귀 → 한계 명확
- 로그 변환 + One-Hot Encoding 필수
- 최종적으로 LightGBM이 가장 우수한 성능
- 실전 캐글 회귀 문제의 전형적인 해결 흐름
반응형
'Programming' 카테고리의 다른 글
| 캐글 주택가격 예측 프로젝트 (2편) : 교차검증, 하이퍼파라미터 튜닝, 왜도 보정, 이상치 제거를 통한 성능 고도화 (0) | 2026.01.09 |
|---|---|
| 캐글 주택가격 예측 프로젝트 (1편) : 고급 회귀 기법을 위한 데이터 이해와 선형 회귀 모델 분석 (0) | 2026.01.09 |
| 로지스틱 회귀와 회귀 트리 기반 모델 이해 (0) | 2026.01.05 |
| 선형회귀 모델을 위한 데이터 변환 전략 정리 (0) | 2026.01.05 |
| Lasso 회귀와 ElasticNet 회귀 이해 및 실습 (1) | 2026.01.05 |