
반응형

이번 프로젝트는 Kaggle의 House Prices: Advanced Regression Techniques 데이터셋을 활용하여
단순 선형회귀를 넘어 로그 변환, 이상치·결측치 처리, 규제 회귀 모델 비교까지 진행하는 고급 회귀 프로젝트입니다.
전체 프로젝트 구성은 다음 3편으로 나뉩니다.
- 1편 (이번 글)
- 데이터 이해
- 타겟값 로그 변환
- 결측치 처리 & 원-핫 인코딩
- 선형 회귀 / Ridge / Lasso 성능 비교 및 회귀계수 분석
- 2편
- 이상치 제거
- 트리 기반 회귀 모델(RandomForest, GBM 등)
- 3편
- 혼합 모델
- 스태킹(Stacking) 기반 최종 성능 개선
1. 데이터 로드 및 기본 환경 설정
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline설명
- warnings.filterwarnings('ignore')
- 경고 메시지가 너무 많이 출력되면 분석 흐름이 끊기므로 비활성화합니다.
- 분석 및 시각화 라이브러리
- pandas / numpy : 데이터 처리
- seaborn / matplotlib : 데이터 분포 및 회귀 계수 시각화
house_df_org = pd.read_csv('./housepricesadvanced/train.csv')
house_df = house_df_org.copy()
house_df.head(3)
설명
- Kaggle 주택가격 학습 데이터를 로드합니다.
- 원본 데이터(house_df_org)를 유지하고,
가공용 데이터(house_df)를 복사본으로 사용합니다. - 이는 실험 중 원본 손상을 방지하기 위한 좋은 습관입니다.
2. 주요 컬럼 개요 (도메인 이해)
주택 가격 예측에서는 면적, 품질, 위치, 연식이 핵심 피처입니다.
- 1stFlrSF, 2ndFlrSF, GrLivArea
→ 주거 면적 관련 핵심 변수 - OverallQual, OverallCond
→ 집의 품질과 상태를 점수화한 변수 - YearBuilt
→ 건축 연도 - Neighborhood, RoofMatl, RoofStyle
→ 위치 및 외관 특성 (범주형 변수)
👉 회귀 모델 성능은 결국 “좋은 피처 이해”에서 시작합니다.
3. 결측치(NaN) 현황 확인
house_df.info()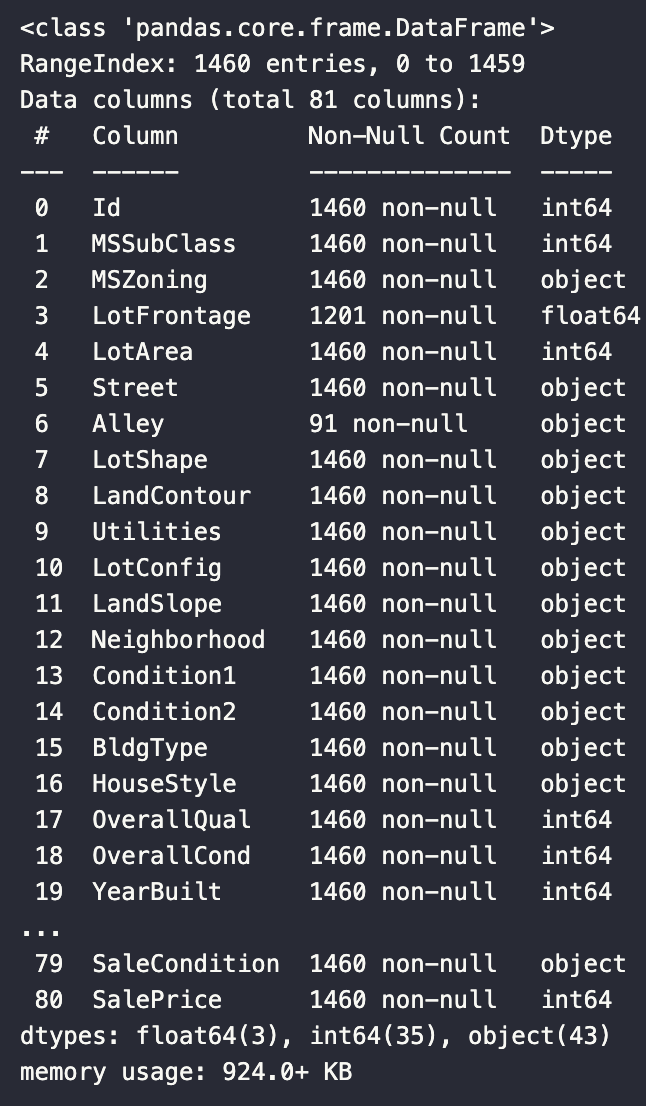
print(house_df.shape)
print(house_df.dtypes.value_counts())
isnull_series = house_df.isnull().sum()
print(f'null 컬럼 및 건수 : {isnull_series[isnull_series>0].sort_values(ascending=False)}')설명
- 데이터 크기, 타입 분포, 결측치 개수를 확인합니다.
- 이 데이터셋은 결측치가 많은 컬럼이 존재하며,
회귀 모델 학습 전 반드시 정리가 필요합니다.
4. 타겟값(SalePrice) 분포 확인
plt.title('Original Sale Price Histogram')
plt.xticks(rotation=15)
sns.histplot(house_df['SalePrice'], kde=True)
plt.show()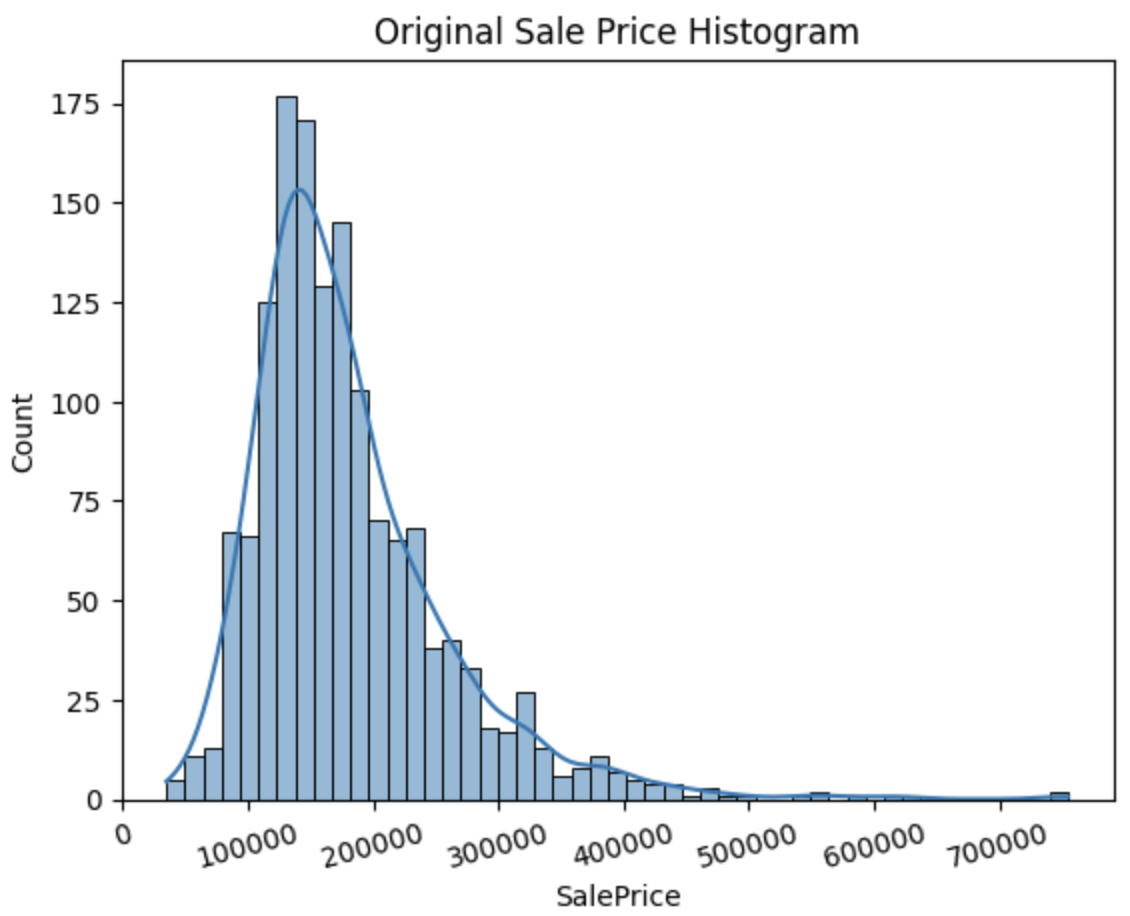
설명
- 주택 가격 분포는 오른쪽으로 긴 꼬리(Right Skew) 형태입니다.
- 이런 분포는 회귀 모델이 고가 주택에 과도하게 끌려가는 문제를 유발합니다.
5. 타겟값 로그 변환 (핵심 Feature Engineering)
plt.title('Log Transformed Sale Price Histogram')
log_SalePrice = np.log1p(house_df['SalePrice'])
sns.histplot(log_SalePrice, kde=True)
plt.show()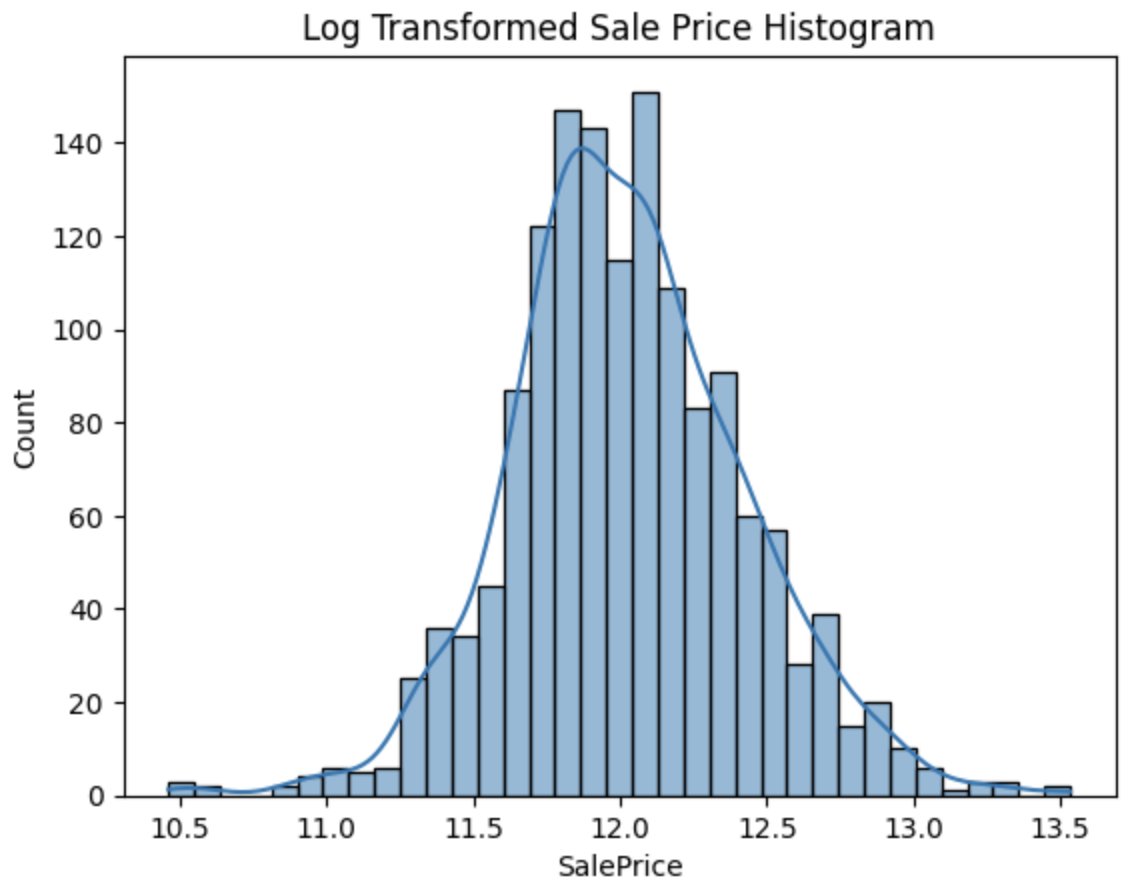
설명
- np.log1p()는 log(1+x)로,
0값이 있어도 안전하게 로그 변환이 가능합니다. - 로그 변환 후 분포가 훨씬 정규분포에 가까워짐을 확인할 수 있습니다.
6. 로그 변환 적용 및 결측치 처리
original_SalePrice = house_df['SalePrice']
house_df['SalePrice'] = np.log1p(house_df['SalePrice'])설명
- 타겟값을 로그 변환하여 모델 학습 안정성을 높입니다.
house_df.drop(
['Id','PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu'],
axis=1,
inplace=True
)설명
- 결측치가 너무 많아 의미 있는 복원이 어려운 컬럼은 제거합니다.
- 이는 불필요한 노이즈를 줄이는 과정입니다.
house_df.fillna(house_df.mean, inplace=True)설명
- 숫자형 컬럼의 결측치는 평균값으로 대체
- 선형 회귀 모델에서 가장 기본적이고 안정적인 방식입니다
null_column_count = house_df.isnull().sum()[house_df.isnull().sum()>0]
print(f'null 피처 타입 : {house_df.dtypes[null_column_count.index]}')설명
- 결측치가 남아 있는 컬럼 타입을 다시 점검합니다.
7. 범주형 변수 원-핫 인코딩
print(f'get dummise 수행 전 shape : {house_df.shape}')
house_df_ohe = pd.get_dummies(house_df)
print(f'get dummise 수행 후 shape : {house_df_ohe.shape}')설명
- 문자열(범주형) 변수를 숫자로 바꾸기 위해 원-핫 인코딩 수행
- 피처 수가 75 → 815개로 증가
- 이는 선형 회귀에서 흔히 발생하는 현상입니다.
null_column_count = house_df_ohe.isnull().sum()[house_df_ohe.isnull().sum()>0]
print(f'Null 피처 타입 : {house_df_ohe[null_column_count.index]}')설명
- 인코딩 후 결측치가 완전히 제거되었는지 최종 확인합니다.
8. 선형 회귀 모델 학습 및 평가
RMSE 계산 함수
from sklearn.metrics import mean_squared_error
def get_rmse(model):
pred = model.predict(X_test)
mse = mean_squared_error(y_test, pred)
rmse = np.sqrt(mse)
print(f'로그 변환 RMSE : {model.__class__.__name__} - {np.round(rmse,3)}')
return rmse설명
- 로그 변환된 타겟값 기준 RMSE를 계산합니다.
- 모델 간 성능 비교용 함수입니다.
def get_rmses(models):
rmses = []
for model in models:
rmses.append(get_rmse(model))
return rmses모델 학습
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice', axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(
X_features,
y_target,
test_size=0.2,
random_state=156
)설명
- 로그 변환된 SalePrice를 타겟으로 설정
- 학습/테스트 데이터 분리
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge()
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso()
lasso_reg.fit(X_train, y_train)
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)
#결과 요약
LinearRegression : 0.166
Ridge : 0.131
Lasso : 0.177
- Ridge가 가장 우수
- Lasso는 회귀계수를 과도하게 줄여 성능 저하 발생
9. 회귀 계수 시각화 (모델 해석)
def get_top_bottom_coef(model):
coef = pd.Series(model.coef_, index=X_features.columns)
coef_high = coef.sort_values(ascending=False).head(10)
coef_low = coef.sort_values(ascending=False).tail(10)
return coef_high, coef_low
def visualize_coefficient(models):
fig, axs = plt.subplots(figsize=(24,10), nrows=1, ncols=3)
fig.tight_layout()
for i_num, model in enumerate(models):
coef_high, coef_low = get_top_bottom_coef(model)
coef_concat = pd.concat([coef_high, coef_low])
axs[i_num].set_title(model.__class__.__name__+' Coeffiecents', size=25)
axs[i_num].tick_params(axis="y", direction="in", pad=-120)
for label in (axs[i_num].get_xticklabels() + axs[i_num].get_yticklabels()):
label.set_fontsize(12)
sns.barplot(x=coef_concat.values, y=coef_concat.index, ax=axs[i_num])
models = [lr_reg, ridge_reg, lasso_reg]
visualize_coefficient(models)

해석
- Lasso는 대부분의 계수를 0에 가깝게 만듦
- 이는 피처 선택에는 유리하지만,
이번 데이터에서는 정보 손실이 큼
✅ 1편 정리
- 타겟값 로그 변환은 성능 개선에 필수
- Ridge 회귀가 가장 안정적인 성능
- Lasso는 계수 축소가 과도해 성능 저하
- 다음 편에서는 이상치 제거 + 트리 기반 회귀 모델을 다룸
반응형
'Programming' 카테고리의 다른 글
| 캐글 주택가격 예측 : 고급 회귀 기법 (3편) : 회귀 트리 모델 · 예측 혼합 · 스태킹(Stacking) 앙상블 (0) | 2026.01.09 |
|---|---|
| 캐글 주택가격 예측 프로젝트 (2편) : 교차검증, 하이퍼파라미터 튜닝, 왜도 보정, 이상치 제거를 통한 성능 고도화 (0) | 2026.01.09 |
| Bike Demand 예측 프로젝트 : 회귀 기반 수요 예측 실전 프로젝트 정리 (0) | 2026.01.09 |
| 로지스틱 회귀와 회귀 트리 기반 모델 이해 (0) | 2026.01.05 |
| 선형회귀 모델을 위한 데이터 변환 전략 정리 (0) | 2026.01.05 |