
반응형

. 로지스틱 회귀(Logistic Regression) 개요
로지스틱 회귀는 이름에 ‘회귀’가 포함되어 있지만 분류(Classification) 문제에 사용되는 대표적인 알고리즘입니다.
기본 아이디어는 선형회귀 모델의 출력값을 그대로 사용하지 않고, 시그모이드(Sigmoid) 함수에 통과시켜 확률값으로 변환한 뒤 이를 기준으로 클래스를 결정하는 방식입니다.
로지스틱 회귀의 핵심 특징
- 이진 분류(0 / 1) 문제에 주로 사용
- 예측 결과는 클래스가 아니라 확률 값
- 시그모이드 함수 출력값 ≥ 0.5 → 클래스 1
시그모이드 함수 출력값 < 0.5 → 클래스 0 - 학습의 목적은 시그모이드 함수의 기울기(W)를 최적화하는 것
- 연산이 가볍고 속도가 빠르며,
**희소 데이터(sparse data)**에 강해 텍스트 분류에 자주 사용됨

2. LogisticRegression 주요 하이퍼파라미터
- penalty
- 규제 유형 (l1, l2)
- C
- 규제 강도의 역수
- 값이 작을수록 규제 강도 ↑
- solver
- 최적화 알고리즘
- lbfgs, liblinear, newton-cg, sag, saga 등
3. 유방암 데이터셋을 이용한 로지스틱 회귀 실습
3.1 데이터 스케일링 및 분할
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 데이터 로드
cancer = load_breast_cancer()
# StandardScaler: 평균 0, 분산 1로 스케일 조정
scaler = StandardScaler()
X_data_scaled = scaler.fit_transform(cancer.data)
# 학습/테스트 분리
X_train, X_test, y_train, y_test = train_test_split(
X_data_scaled,
cancer.target,
test_size=0.3,
random_state=0
)로지스틱 회귀는 피처 스케일에 민감하므로 반드시 스케일링이 필요합니다.
3.2 기본 로지스틱 회귀 학습 및 평가
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
print(f'accuracy : {accuracy_score(y_test, lr_preds)}')
print(f'roc_auc : {roc_auc_score(y_test, lr_preds)}')
- Accuracy: 전체 예측 중 맞춘 비율
- ROC-AUC: 분류 성능을 확률 관점에서 평가하는 지표
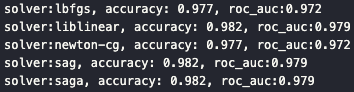
3.3 Solver별 성능 비교
solvers = ['lbfgs', 'liblinear', 'newton-cg', 'sag', 'saga']
for solver in solvers:
lr_clf = LogisticRegression(solver=solver, max_iter=600)
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
print(
'solver:{0}, accuracy:{1:.3f}, roc_auc:{2:.3f}'.format(
solver,
accuracy_score(y_test, lr_preds),
roc_auc_score(y_test, lr_preds)
)
)
데이터 크기와 규제 방식에 따라 solver 성능이 달라질 수 있음
3.4 GridSearchCV를 이용한 하이퍼파라미터 최적화
from sklearn.model_selection import GridSearchCV
params = {
'solver': ['liblinear', 'lbfgs'],
'penalty': ['l2', 'l1'],
'C': [0.01, 0.1, 1, 5, 10]
}
lr_clf = LogisticRegression()
grid_clf = GridSearchCV(
lr_clf,
param_grid=params,
scoring='accuracy',
cv=3
)
grid_clf.fit(X_data_scaled, cancer.target)
print(
f'최적 하이퍼파라미터:{grid_clf.best_params_}, '
f'최적 평균 정확도:{grid_clf.best_score_:.3f}'
)
4. 회귀 트리(Regression Tree) 개요
사이킷런의 트리 기반 알고리즘은 분류뿐 아니라 회귀 문제도 해결 가능합니다.
이는 결정트리가 CART(Classification And Regression Tree) 알고리즘을 기반으로 만들어졌기 때문입니다.
회귀 트리의 특징
- 데이터를 기준(feature, threshold)에 따라 반복적으로 분할
- 최종 리프 노드에서는 해당 영역 데이터의 평균값으로 예측
- 복잡한 트리는 과적합에 매우 취약
- max_depth, min_samples_leaf 등으로 제어 필요
5. 트리 기반 회귀 모델 성능 비교 (보스턴 주택 가격)
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
#공통평가함수
def get_model_cv_prediction(model, X_data, y_target):
neg_mse_scores = cross_val_score(
model,
X_data,
y_target,
scoring='neg_mean_squared_error',
cv=5
)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
print(model.__class__.__name__)
print(f'5차 교차검증 평균 RMSE : {np.mean(rmse_scores)}')
#모델별 성능 평가
models = [
DecisionTreeRegressor(max_depth=4),
RandomForestRegressor(n_estimators=1000),
GradientBoostingRegressor(n_estimators=1000),
XGBRegressor(n_estimators=1000),
LGBMRegressor(n_estimators=1000)
]
for model in models:
get_model_cv_prediction(model, X_data, y_target)일반적으로 단일 트리 < 앙상블 트리 순으로 성능이 향상됨
DecisionTreeRegressor 5차 교차검증의 평균 RMSE : 5.977957424580515
RandomForestRegressor 5차 교차검증의 평균 RMSE : 4.419275850149559
GradientBoostingRegressor 5차 교차검증의 평균 RMSE : 4.268931715624839
XGBRegressor 5차 교차검증의 평균 RMSE : 4.251080362834295
LGBMRegressor 5차 교차검증의 평균 RMSE : 4.646441191925675
6. 회귀 트리 시각화: 선형 회귀 vs 트리 회귀
핵심 비교 포인트
- 선형 회귀: 하나의 직선 → 과소적합 가능성
- 결정 트리 (depth 낮음): 완만한 계단 → 적절한 일반화
- 결정 트리 (depth 높음): 요철 많은 계단 → 과적합 위험
max_depth가 커질수록 모델 복잡도 증가
→ 학습 데이터에는 잘 맞지만 새로운 데이터에는 취약
import matplotlib.pyplot as plt
%matplotlib inline
bostonDF_sample = bostonDF[['RM','PRICE']]
bostonDF_sample = bostonDF_sample.sample(n=100,random_state=0)
print(bostonDF_sample.shape)
plt.figure()
plt.scatter(bostonDF_sample.RM , bostonDF_sample.PRICE,c="darkorange")
import numpy as np
from sklearn.linear_model import LinearRegression
# (필수) DecisionTreeRegressor를 사용하므로 아래 임포트가 필요합니다.
# from sklearn.tree import DecisionTreeRegressor
# (필수) 시각화를 위해 matplotlib.pyplot 임포트가 필요합니다.
# import matplotlib.pyplot as plt
# -------------------------------------------------------------------
# 1) 모델(추정기, Estimator) 생성
# -------------------------------------------------------------------
# 목적: 같은 데이터(RM -> PRICE)에 대해
# - 선형 회귀(Linear Regression) 모델이 만드는 예측 곡선(직선)
# - 결정트리 회귀(DecisionTreeRegressor)가 만드는 예측 곡선(계단 형태)
# 을 비교하여 "모델 복잡도(max_depth)에 따라 과소적합/과적합이 어떻게 나타나는지" 시각적으로 보여주려는 코드입니다.
# 선형 회귀 모델 생성
# 기능: 입력 X와 타깃 y의 관계를 "직선(1차 함수)" 형태로 근사합니다.
# 학습 시 최소제곱(OLS)을 통해 기울기(coef_)와 절편(intercept_)를 추정합니다.
lr_reg = LinearRegression()
# 결정 트리 기반 회귀 모델 생성 (max_depth=2)
# 기능: 데이터를 여러 규칙(분기)으로 나누어 각 영역(리프 노드)에서 평균값으로 예측하는 비선형 모델입니다.
# max_depth=2는 트리의 깊이를 2로 제한하여 모델 복잡도를 낮게 유지합니다.
# -> 보통 "부드럽게" 근사하며, 과소적합(underfitting) 경향이 있을 수 있습니다.
rf_reg2 = DecisionTreeRegressor(max_depth=2)
# 결정 트리 기반 회귀 모델 생성 (max_depth=7)
# 기능: max_depth=7은 더 많은 분기를 허용하여 더 복잡한 규칙을 학습할 수 있습니다.
# -> 데이터의 세부 패턴까지 따라가려 하므로, 과적합(overfitting) 가능성이 커집니다.
rf_reg7 = DecisionTreeRegressor(max_depth=7)
# -------------------------------------------------------------------
# 2) 테스트용 X축(입력) 그리드 생성
# -------------------------------------------------------------------
# 목적: 학습 데이터의 RM 범위(대략 4.5~8.5)에 대해
# 촘촘한 X값들을 만들어 모델 예측선을 부드럽게 그리기 위함입니다.
# 기능: 4.5 이상 8.5 미만 범위를 0.04 간격으로 생성 -> 약 100개 포인트.
# reshape(-1, 1)은 scikit-learn이 요구하는 2차원 입력 형태(n_samples, n_features)로 변환합니다.
# (여기서는 피처가 1개(RM)이므로 n_features=1)
X_test = np.arange(4.5, 8.5, 0.04).reshape(-1, 1)
# -------------------------------------------------------------------
# 3) 학습에 사용할 피처(X)와 타깃(y) 추출
# -------------------------------------------------------------------
# 목적: 보스턴 주택가격 데이터에서 시각화를 단순화하기 위해
# 여러 피처 중 RM(평균 방 개수) 한 개만 사용해서 PRICE를 예측하는 구조로 만듭니다.
# 기능:
# - bostonDF_sample['RM'] : RM 컬럼만 선택
# - .values : pandas Series/DataFrame을 numpy 배열로 변환
# - reshape(-1, 1) : (샘플 수, 1개 피처) 형태로 변환
#
# 주의: bostonDF_sample이 미리 정의되어 있어야 합니다.
# (예: bostonDF에서 일부 샘플만 추출한 DataFrame)
X_feature = bostonDF_sample['RM'].values.reshape(-1, 1)
# 타깃(정답) 값인 PRICE 추출
# 기능:
# - PRICE 컬럼을 numpy 배열로 변환 후 reshape(-1, 1)
#
# 참고: scikit-learn의 많은 회귀 모델은 y를 (n_samples,) 1차원으로도 받습니다.
# 즉 아래처럼 해도 보통 됩니다:
# y_target = bostonDF_sample['PRICE'].values
# 하지만 여기서는 일관성을 위해 (n_samples, 1)로 맞춰둔 형태입니다.
y_target = bostonDF_sample['PRICE'].values.reshape(-1, 1)
# -------------------------------------------------------------------
# 4) 모델 학습(fit)
# -------------------------------------------------------------------
# 목적: 각 모델이 (RM -> PRICE)의 관계를 학습하도록 만듭니다.
# 기능:
# - fit(X, y)는 훈련 데이터로 모델 내부 파라미터(회귀계수 또는 트리 분기 규칙)를 학습합니다.
# - 선형 회귀는 직선 계수를 학습하고,
# - 결정 트리는 데이터를 잘 나누는 규칙(임계값)과 각 리프의 예측값(평균)을 학습합니다.
lr_reg.fit(X_feature, y_target)
rf_reg2.fit(X_feature, y_target)
rf_reg7.fit(X_feature, y_target)
# -------------------------------------------------------------------
# 5) 예측(predict)
# -------------------------------------------------------------------
# 목적: 4.5~8.5 범위의 촘촘한 X_test에 대해 모델이 예측하는 PRICE를 계산하여
# "예측 곡선"을 그릴 수 있게 합니다.
# 기능:
# - predict(X_test)는 각 X_test 입력에 대해 y(PRICE) 예측값을 반환합니다.
# - 선형 회귀는 직선 형태로 출력되며,
# - 결정 트리는 구간별 상수값(계단 형태)로 출력되는 경향이 있습니다.
pred_lr = lr_reg.predict(X_test)
pred_rf2 = rf_reg2.predict(X_test)
pred_rf7 = rf_reg7.predict(X_test)
# -------------------------------------------------------------------
# 6) 시각화: 1행 3열의 서브플롯 생성
# -------------------------------------------------------------------
# 목적: 동일한 데이터에 대해
# - 선형 회귀
# - 결정트리(depth=2)
# - 결정트리(depth=7)
# 결과를 한 화면에서 비교하기 위함입니다.
#
# 기능:
# - plt.subplots(figsize=(14,4), ncols=3)
# -> 가로로 3개의 축(ax1, ax2, ax3)을 생성
# - figsize=(14,4) -> 그림 크기(가로 14, 세로 4)
fig, (ax1, ax2, ax3) = plt.subplots(figsize=(14, 4), ncols=3)
# -------------------------------------------------------------------
# 7) 그래프 1: 선형 회귀 결과
# -------------------------------------------------------------------
# 제목 설정
ax1.set_title('Linear Regression')
# 산점도(scatter)
# 목적: 실제 데이터 분포(RM, PRICE)를 점으로 표시하여 모델 예측선과 비교하기 위함
# 기능: x축은 RM, y축은 PRICE
ax1.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
# 예측선(plot)
# 목적: X_test(촘촘한 RM값)에 대한 예측 PRICE(pred_lr)를 선으로 그려 모델의 추세를 확인
# 기능:
# - linewidth=2 : 선 두께
# - label="linear" : 범례에 표시할 라벨(범례를 표시하려면 ax.legend() 호출이 필요)
ax1.plot(X_test, pred_lr, label="linear", linewidth=2)
# -------------------------------------------------------------------
# 8) 그래프 2: 결정 트리 (max_depth=2) 결과
# -------------------------------------------------------------------
ax2.set_title('Decision Tree Regression: \n max_depth=2')
ax2.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
# 결정트리 예측선은 보통 계단 형태가 됩니다.
# 이유: 트리가 입력 구간을 여러 구간으로 분할하고, 각 구간(리프)에서 평균값으로 예측하기 때문입니다.
ax2.plot(X_test, pred_rf2, label="max_depth:2", linewidth=2)
# -------------------------------------------------------------------
# 9) 그래프 3: 결정 트리 (max_depth=7) 결과
# -------------------------------------------------------------------
ax3.set_title('Decision Tree Regression: \n max_depth=7')
ax3.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
# max_depth가 커질수록 더 잘게 구간을 나눌 수 있어
# 학습 데이터에 더 밀착된(요철이 많은) 예측선이 나올 수 있습니다.
# 이는 성능 향상을 가져올 수도 있지만, 일반화 성능을 해칠 정도로 과적합을 유발할 수도 있습니다.
ax3.plot(X_test, pred_rf7, label="max_depth:7", linewidth=2)
# (권장) 범례 표시: 각 subplot마다 label을 달았으므로 legend를 호출하면 선의 의미가 명확해집니다.
# ax1.legend()
# ax2.legend()
# ax3.legend()
# (권장) 레이아웃 정리: 제목/축 라벨이 겹치지 않게 간격 자동 조정
# plt.tight_layout()
# plt.show()
#max_depth이 늘수록 오버피팅하기쉬움
7. 정리
- 로지스틱 회귀는 확률 기반 분류 모델
- 회귀 트리는 비선형 관계를 잘 포착하지만 과적합 주의
- 트리 기반 앙상블(RandomForest, GBM, XGBoost, LightGBM)은
회귀 문제에서 매우 강력 - 모델 성능은 복잡도 제어가 핵심
반응형
'Programming' 카테고리의 다른 글
| 캐글 주택가격 예측 프로젝트 (1편) : 고급 회귀 기법을 위한 데이터 이해와 선형 회귀 모델 분석 (0) | 2026.01.09 |
|---|---|
| Bike Demand 예측 프로젝트 : 회귀 기반 수요 예측 실전 프로젝트 정리 (0) | 2026.01.09 |
| 선형회귀 모델을 위한 데이터 변환 전략 정리 (0) | 2026.01.05 |
| Lasso 회귀와 ElasticNet 회귀 이해 및 실습 (1) | 2026.01.05 |
| 규제 선형회귀(Regularized Linear Regression)와 Ridge 회귀 실습 (1) | 2026.01.05 |