
반응형

1. 왜 데이터 분포 변환이 필요한가?
신용카드 사기 탐지 데이터는 다음과 같은 특징을 가집니다.
- 거래 금액(Amount) 은 극단적으로 한쪽에 몰린 분포를 가짐
- 대부분의 거래는 소액이며, 일부 고액 거래가 꼬리 형태로 존재
- 이런 왜곡된 분포(Skewed Distribution) 는
- 선형 모델(Logistic Regression)의 학습을 방해하고
- 거리 기반/확률 기반 모델의 성능을 저하시킴
따라서 모델 학습 전에 데이터 분포를 보다 정규분포에 가깝게 변환하는 Feature Engineering이 필요합니다.
2. Amount 컬럼 분포 확인
### 데이터 분포도 변환 후 모델 학습 예측 평가
#중요 피쳐 분포확인
import seaborn as sns
plt.figure(figsize=(8,4))
plt.xticks(range(0,30000,1000),rotation=60)
sns.histplot(card_df['Amount'],bins=100,kde=True)
plt.show()
해석
- Amount 컬럼은 거의 모든 값이 0 근처에 몰려 있음
- 일부 큰 값들이 오른쪽 꼬리를 길게 끌고 있음
- 이 상태로 학습 시 모델은 금액 정보의 상대적 중요도를 제대로 학습하지 못함
➡️ StandardScaler 또는 Log 변환 필요
3. StandardScaler를 이용한 분포 변환
StandardScaler 개념
- 평균을 0, 표준편차를 1로 맞추는 정규화 방식
- 값의 스케일 차이를 제거하는 데 효과적
- 이상치 자체를 제거하지는 않음
StandardScaler 적용 코드
from sklearn.preprocessing import StandardScaler
#데이터 전처리를 위해 별도 함수에 StandardScaler이용 > amount피쳐변환
def get_prepreocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
amount_n=scaler.fit_transform(df_copy['Amount'].values.reshape(-1,1)) #StandardScaler는 2차원 array를 넣어야하므로 형변환
df_copy.insert(0,'Amount_Scaled',amount_n) #변환 값 컬럼으로 삽입
df_copy.drop(['Time','Amount'], axis=1, inplace = True)
return df_copy
학습 / 테스트 데이터 분리
def get_train_test_dataset(df=None):
df_copy = get_prepreocessed_df(df)
X_features = df_copy.iloc[:,:-1]
y_target = df_copy.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(
X_features, y_target,
test_size=0.3,
random_state=0,
stratify=y_target
)
return X_train, X_test, y_train, y_test4. StandardScaler 적용 후 모델 성능 평가
Logistic Regression
#StandardScaler 변환후 로지스틱, LigtGBM학습 예측 평가 > 위에서 작성한 모델, 학습, 평가 함수 활용
#-LogisticRegression
print(f'Logistic 성능')
lr_clf=LogisticRegression(max_iter=1000)
get_model_train_eval(lr_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test)
# Logistic 성능
# Confusion Matrix
# [[85281 14]
# [ 58 90]]
# (1)정확도 : 0.9991573329588147
# (2)정밀도 : 0.8653846153846154
# (3)재현율 : 0.6081081081081081
# (4)F1 : 0.7142857142857144
# (5)roc_auc : 0.9702267805058122해석
- 정확도는 매우 높지만 사기 거래 재현율(Recall)은 약 60%
- 실제 사기 거래 중 약 40%를 놓치고 있음
- 금융 사기 탐지에서는 Recall이 매우 중요
LightGBM
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-2,
boost_from_average=False
)
get_model_train_eval(
lgbm_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test)
# Confusion Matrix
# [[85290 5]
# [ 37 111]]
# (1)정확도 : 0.9995084442259752
# (2)정밀도 : 0.9568965517241379
# (3)재현율 : 0.75
# (4)F1 : 0.8409090909090909
# (5)roc_auc : 0.9778719483889774해석
- Logistic 대비 재현율이 0.75로 개선
- 하지만 여전히 더 끌어올릴 여지가 있음
- StandardScaler만으로는 큰 개선 효과는 제한적
5. log1p / expm1 변환 개념 이해
print(1e-1000==0.0)
print(np.log(1e-1000))
print(np.log(1e-1000+1))
print(np.log1p(1e-1000))
var_1=np.log1p(100)
var_2=np.expm1(var_1)
print(var_1,var_2)핵심 개념 정리
- log(0) 은 -inf 발생
- log1p(x) = log(1 + x)
- 0 또는 매우 작은 값에서도 안전
- expm1(x) = exp(x) - 1
- log 변환의 역변환에 사용
➡️ 금융 데이터처럼 0에 가까운 값이 많은 경우 log1p가 매우 유리
6. log1p 기반 Amount 변환
def get_prepreocessed_df(df=None):
df_copy = df.copy()
amount_n=np.log1p(df_copy['Amount']) #로그변환
df_copy.insert(0,'Amount_Scaled',amount_n)
df_copy.drop(['Time','Amount'], axis=1, inplace = True)
return df_copy7. log 변환 후 모델 성능 평가
Logistic Regression
lr_clf=LogisticRegression(max_iter=1000)
get_model_train_eval(lr_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test)
# Logistic 성능
# Confusion Matrix
# [[85283 12]
# [ 59 89]]
# (1)정확도 : 0.99916903666772
# (2)정밀도 : 0.8811881188118812
# (3)재현율 : 0.6013513513513513
# (4)F1 : 0.714859437751004
# (5)roc_auc : 0.9726832788589045➡️ Logistic은 큰 변화 없음
LightGBM
#-LigtGBM
print(f'LigtGBM 성능')
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-2,
boost_from_average=False
)
get_model_train_eval(
lgbm_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test)
# Confusion Matrix
# [[85290 5]
# [ 35 113]]
# (1)정확도 : 0.9995318516437859
# (2)정밀도 : 0.9576271186440678
# (3)재현율 : 0.7635135135135135
# (4)F1 : 0.849624060150376
# (5)roc_auc : 0.9796242927962255➡️ 재현율, F1, ROC-AUC 모두 개선
8. log 변환 후 Amount 분포 확인
plt.figure(figsize=(8,4))
plt.xticks(range(0,30000,1000),rotation=60)
sns.histplot(X_train['Amount_Scaled'],bins=100,kde=True)
plt.show()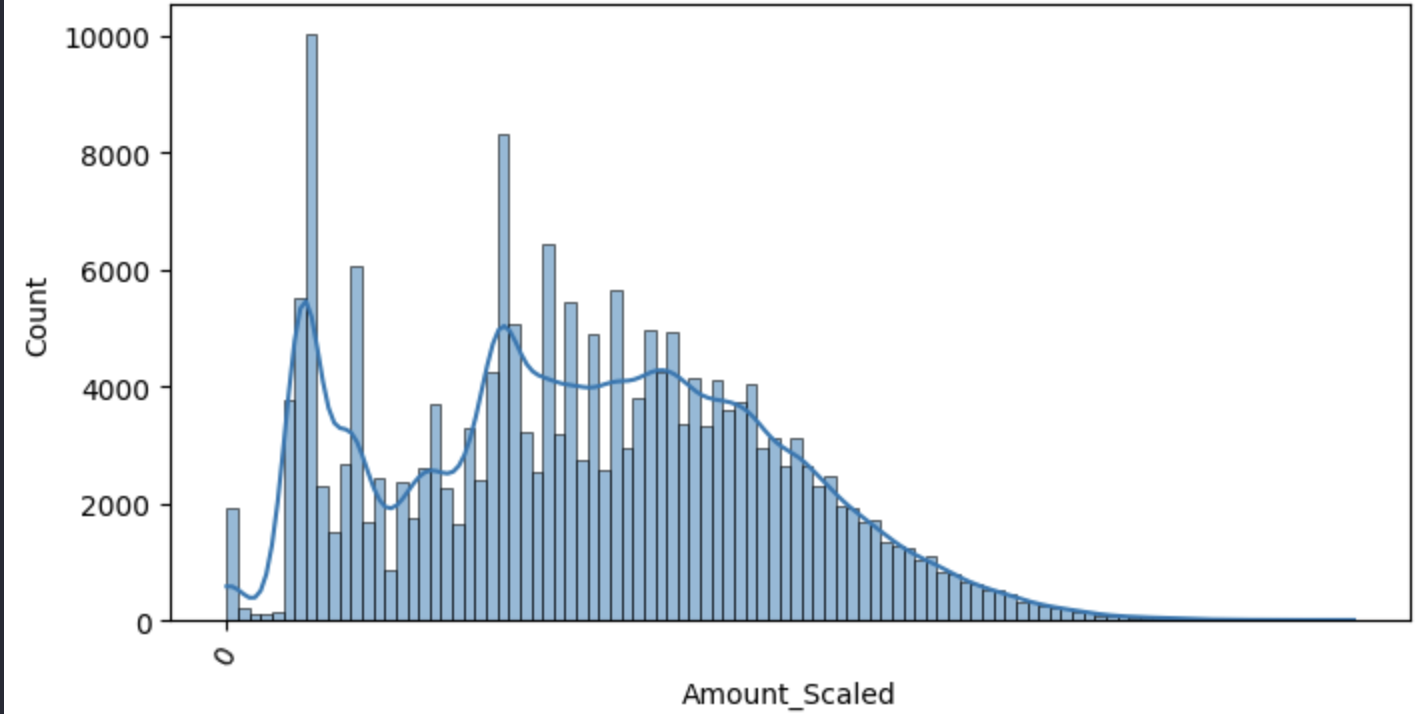
| StandardScaler | 성능 개선 제한적 |
| log1p 변환 | LightGBM 성능 유의미 개선 |
| 핵심 포인트 | 분포 왜곡이 심한 피처는 로그 변환이 효과적 |
| 한계 | 여전히 재현율을 더 끌어올릴 필요 있음 |
반응형
'Programming' 카테고리의 다른 글
| Stacking Ensemble 실습 : Basic Stacking과 교차검증 기반 Stacking 이해하기 (0) | 2025.12.31 |
|---|---|
| Credit Card Fraud Detection 3편 : 이상치 제거(IQR)와 SMOTE 오버샘플링을 통한 성능 개선 (0) | 2025.12.26 |
| Credit Card Fraud Detection 1편 : Feature Engineering과 Baseline 모델 성능 분석 (0) | 2025.12.26 |
| IQR과 SMOTE 이해하기 (1) | 2025.12.26 |
| Customer Satisfaction 예측 프로젝트 (XGBoost/LightGBM + HyperOpt 튜닝) (0) | 2025.12.26 |