
반응형

신용카드 사기 탐지는 대표적인 극심한 클래스 불균형(Class Imbalance) 문제입니다.
전체 거래 중 사기 거래 비율은 0.2% 미만으로, 단순 정확도(Accuracy)만으로는 모델 성능을 제대로 평가할 수 없습니다.
본 글(1편)에서는 다음을 목표로 합니다.
- 원본 데이터의 레이블 불균형 구조 파악
- Feature Engineering 이전 상태에서의 Baseline 모델 성능 확인
- Logistic Regression, LightGBM의 기본 성능 비교
- 왜 이후 단계에서 Feature Engineering이 필수적인지 문제의식 정리
데이터 로드 및 기본 구조 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
card_df = pd.read_csv('./creditCard/creditcard.csv')
card_df.head(3)
# amount 중요 컬럼
card_df.shape
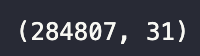
- creditcard.csv 데이터는 유럽 카드 거래 데이터로,
- Class 컬럼이 타겟 레이블입니다.
- 0 : 정상 거래
- 1 : 사기 거래
- Amount 컬럼은 거래 금액으로 유일한 원본 스케일 피처입니다.
데이터 전처리 함수 구성
Time 컬럼 제거
from sklearn.model_selection import train_test_split
def get_prepreocessed_df(df=None):
df_copy = df.copy()
df_copy.drop('Time', axis=1, inplace = True)
return df_copy
- Time 컬럼은 거래 발생 시점을 나타내지만,
- 본 실험에서는 모델 성능에 직접적인 의미를 주기 어렵다고 판단하여 제거합니다.
- 원본 데이터 보호를 위해 항상 copy()를 사용합니다.
학습 / 테스트 데이터 분리
def get_train_test_dataset(df=None):
df_copy = get_prepreocessed_df(df)
X_features = df_copy.iloc[:,:-1]
y_target = df_copy.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(
X_features,
y_target,
test_size=0.3,
random_state=0,
stratify=y_target
)
return X_train, X_test, y_train, y_test
- Train : Test = 70 : 30
- stratify=y_target을 적용하여
→ 사기/정상 비율이 학습·테스트 데이터에서 동일하게 유지되도록 합니다.
레이블 불균형 확인
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print(f'학습 데이터 레이블 값 비율 : {y_train.value_counts()/y_train.shape[0]*100}')
print(f'테스트 데이터 레이블 값 비율 : {y_test.value_counts()/y_test.shape[0]*100}')
실행 결과:
- 학습 데이터
- 정상(Class 0): 99.83%
- 사기(Class 1): 0.17%
- 테스트 데이터 역시 동일한 비율을 유지합니다.
👉 모델은 아무런 처리 없이 학습할 경우 정상 거래만 예측해도 높은 정확도를 얻게 되는 구조입니다.
모델 평가 함수 정의
from sklearn.metrics import confusion_matrix,accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba = None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test,pred)
f1 = f1_score(y_test,pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print(
f"Confusion Matrix\n{confusion}\n"
f"(1)정확도 : {accuracy}\n"
f"(2)정밀도 : {precision}\n"
f"(3)재현율 : {recall}\n"
f"(4)F1 : {f1}\n"
f"(5)roc_auc : {roc_auc}"
)
- 사기 탐지 문제에서는 **재현율(Recall)**이 가장 중요합니다.
- 단 하나의 사기 거래라도 놓치지 않는 것이 비즈니스적으로 더 중요하기 때문입니다.
Baseline ① Logistic Regression
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter=1000)
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
lr_pred_proba = lr_clf.predict_proba(X_test)[:,1]
get_clf_eval(y_test, lr_pred, lr_pred_proba)
결과 해석
[[85281 14]
[ 58 90]]
- 실제 사기 거래 중 58건을 놓침(False Negative)
- 재현율(Recall): 0.608
👉 정확도는 99.9%로 매우 높지만
👉 사기 거래의 약 40%를 놓치는 심각한 문제가 있습니다.
공통 학습/평가 함수 구성
def get_model_train_eval(model, ftr_train=None,ftr_test=None, tgt_train=None, tgt_test=None):
model.fit(ftr_train, tgt_train)
pred=model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:,1]
get_clf_eval(y_test, pred, pred_proba)이후 Feature Engineering을 적용할 때
모델 구조는 그대로 두고 데이터만 변경하여 성능 비교하기 위함입니다.
Baseline ② LightGBM
boost_from_average 설명
- LightGBM 2.1.0 이상에서는 boost_from_average=True가 기본값입니다.
- 클래스 불균형이 극심한 경우:
- 초기 score가 평균값 기준으로 설정되면서
- 재현율과 ROC-AUC가 급격히 저하될 수 있습니다.
- 따라서 사기 탐지에서는 False로 설정하는 것이 유리합니다.
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1,
boost_from_average=False
)
get_model_train_eval(
lgbm_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test
)
[[85290 5]
[ 36 112]]- 재현율(Recall): 0.756
- Logistic Regression 대비 사기 검출 성능이 확연히 개선
👉 하지만 여전히 약 25%의 사기 거래를 놓침
| 모델 | Recall | ROC-AUC |
| Logistic Regression | 0.608 | 0.970 |
| LightGBM | 0.756 | 0.979 |
- 단순 모델 학습만으로는 사기 탐지 성능에 명확한 한계가 존재합니다.
- 다음 문제가 확인됩니다.
- 거래 금액(Amount) 분포 왜곡
- 이상치(Outlier) 존재
- 극단적인 클래스 불균형
👉 2편에서는 Feature Engineering(분포 변환, 이상치 제거, SMOTE)을 통해 이 문제를 단계적으로 개선합니다.
반응형
'Programming' 카테고리의 다른 글
| Credit Card Fraud Detection 3편 : 이상치 제거(IQR)와 SMOTE 오버샘플링을 통한 성능 개선 (0) | 2025.12.26 |
|---|---|
| Credit Card Fraud Detection 2편 : 데이터 분포도 변환 후 모델 학습·예측·평가 (0) | 2025.12.26 |
| IQR과 SMOTE 이해하기 (1) | 2025.12.26 |
| Customer Satisfaction 예측 프로젝트 (XGBoost/LightGBM + HyperOpt 튜닝) (0) | 2025.12.26 |
| (Bayesian Optimization 2편) HyperOpt로 XGBoost 하이퍼파라미터 튜닝 실습 (0) | 2025.12.22 |