
반응형

1. 개요
이전 편에서는 데이터 분포 변환(StandardScaler, Log 변환) 까지 수행했습니다.
이번 글에서는 다음 두 가지 핵심 Feature Engineering을 적용합니다.
- IQR 기반 이상치 제거
- SMOTE 오버샘플링을 통한 불균형 데이터 보정
신용카드 사기 탐지 문제의 핵심은 정확도(Accuracy) 가 아니라
👉 재현율(Recall) 과 ROC-AUC 입니다.
즉, 사기를 놓치지 않는 것이 가장 중요합니다.
2. 피처 상관관계 분석 (이상치 제거 대상 선정)
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12,12))
corr = card_df.corr()
sns.heatmap(corr, cmap='RdBu', annot=True, fmt='.1f')

해석
- Class(사기 여부)와 음의 상관관계가 강한 피처
- V14
- V17
- 특히 V14는 사기 거래(Class=1)에서 극단적인 값(이상치) 이 많이 존재함
- 따라서 V14를 기준으로 IQR 기반 이상치 제거 수행
3. IQR 기반 이상치 제거 함수 정의
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class'] == 1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
outlier_index = fraud[
(fraud < lowest_val) | (fraud > highest_val)
].index
return outlier_index개념 설명
- IQR (Inter Quartile Range)
- 25% ~ 75% 구간을 기준으로 분포의 중앙 영역을 정의
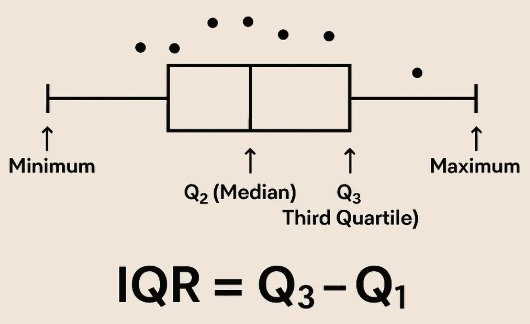
- 이 범위를 벗어난 데이터는 극단값(Outlier) 로 간주
- 사기 데이터(Class=1)에 대해서만 적용 → 정상 데이터 손실 최소화
4. 로그 변환 + 이상치 제거 전처리 파이프라인
def get_prepreocessed_df(df=None):
df_copy = df.copy()
# Amount 로그 변환 (왜곡된 분포 완화)
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
# V14 이상치 제거
outlier_index = get_outlier(df=df_copy, column='V14', weight=1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copy5. 학습 / 테스트 데이터 분리
from sklearn.model_selection import train_test_split
def get_train_test_dataset(df=None):
df_copy = get_prepreocessed_df(df)
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(
X_features,
y_target,
test_size=0.3,
random_state=0,
stratify=y_target
)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)6. 이상치 제거 후 모델 성능 비교
(1) Logistic Regression
from sklearn.linear_model import LogisticRegression
print("Logistic 성능")
lr_clf = LogisticRegression(max_iter=1000)
get_model_train_eval(
lr_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test
)
재현율(Recall) : 0.6712
ROC-AUC : 0.9742
- 이전 대비 재현율 개선
- 이상치 제거가 사기 탐지에 긍정적인 효과를 줌
(2) LightGBM
from lightgbm import LGBMClassifier
print("LightGBM 성능")
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-2,
boost_from_average=False
)
get_model_train_eval(
lgbm_clf,
ftr_train=X_train,
ftr_test=X_test,
tgt_train=y_train,
tgt_test=y_test
)
재현율(Recall) : 0.8287
F1 Score : 0.8897
ROC-AUC : 0.9780
- 실무적으로 매우 우수한 수준
- 사기 탐지 모델로 사용 가능 수준
7. SMOTE 오버샘플링 적용
SMOTE 개념 정리
- Synthetic Minority Over Sampling Technique
- 소수 클래스(Class=1)를 선형 보간 방식으로 증식
- 반드시 학습 데이터에만 적용
- 테스트/검증 데이터에 적용 시 → 데이터 누수(Data Leakage)
import imblearn
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
print(X_train.shape, y_train.shape)
print(X_train_over.shape, y_train_over.shape)
print(pd.Series(y_train_over).value_counts())
8. SMOTE + Logistic Regression
lr_clf = LogisticRegression(max_iter=1000)
get_model_train_eval(
lr_clf,
ftr_train=X_train_over,
ftr_test=X_test,
tgt_train=y_train_over,
tgt_test=y_test
)
재현율(Recall) : 0.9246 (대폭 상승)
정밀도(Precision) : 0.054
- 사기 거의 다 잡음
- 하지만 정상 거래를 너무 많이 사기로 오탐
- 단독 사용은 위험 → Threshold 조정 또는 트리 계열 필요
Precision-Recall Curve 시각화
from sklearn.metrics import precision_recall_curve
precision_recall_curve_plot(
y_test,
lr_clf.predict_proba(X_test)[:,1]
)

Threshold 변화에 따른 정밀도/재현율 Trade-off 확인 가능 하지만 너무 극단적임.
9. SMOTE + LightGBM (최종)
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1,
boost_from_average=False
)
get_model_train_eval(
lgbm_clf,
ftr_train=X_train_over,
ftr_test=X_test,
tgt_train=y_train_over,
tgt_test=y_test
)
재현율(Recall) : 0.8493
정밀도(Precision) : 0.9117
F1 Score : 0.8794
ROC-AUC : 0.9813👉 정밀도와 재현율의 균형이 가장 좋음
10. 결론
| 로그 변환 | 분포 왜곡 완화 |
| IQR 이상치 제거 | 재현율 개선 |
| SMOTE | 사기 탐지 민감도 극대화 |
| LightGBM | 불균형 데이터에 강함] |
실무 추천 조합
👉 Log 변환 + IQR 이상치 제거 + SMOTE + LightGBM
반응형
'Programming' 카테고리의 다른 글
| Feature Selection 실전 : 정리모델 성능과 해석력을 동시에 잡는 방법 (0) | 2026.01.01 |
|---|---|
| Stacking Ensemble 실습 : Basic Stacking과 교차검증 기반 Stacking 이해하기 (0) | 2025.12.31 |
| Credit Card Fraud Detection 2편 : 데이터 분포도 변환 후 모델 학습·예측·평가 (0) | 2025.12.26 |
| Credit Card Fraud Detection 1편 : Feature Engineering과 Baseline 모델 성능 분석 (0) | 2025.12.26 |
| IQR과 SMOTE 이해하기 (1) | 2025.12.26 |