
반응형
📌 개요
이번 글에서는 Titanic 데이터로 연속형/범주형 분포를 더 깊게 보는 시각화를 정리합니다.
특히 초보자들이 자주 헷갈리는 포인트인
- Violin plot이 “히스토그램 + 박스플롯” 느낌인 이유
- Box plot이 4분위를 어떻게 보여주는지
- Subplots에서 ax를 넘겨 여러 그래프를 한 번에 그리는 법
- Scatterplot으로 관계(패턴) 확인
- 상관관계를 Heatmap으로 한 번에 보는 법
을 한 번에 정리합니다.
✅ 요청하신 대로 코드는 한 줄도 줄이지 않고 그대로 포함합니다.
1️⃣ Violin Plot (바이올린 플롯)
✅ 개념/목적
Violin plot은 **연속형 값의 분포(밀도)**를 “대칭 형태”로 보여줍니다.
- 히스토그램처럼 분포 모양을 보여주고
- Box plot처럼 중앙 경향(중앙값, 사분위 등) 정보도 같이 담을 수 있습니다(옵션/기본 표시 방식에 따라 다름)
✅ 언제 쓰나?
단일 컬럼 분포도도 가능하지만, 실무에서는 보통 다음이 핵심입니다.
- X축: 범주형(이산값)
- Y축: 연속형 값
즉, “등급별 나이 분포”, “성별 요금 분포”처럼 범주별 분포 비교에 매우 강력합니다.
### violin plot
- 단일 컬럼에 대해서는 히스토그램과 유사하게 연속값의 분포도를 시각화 또한 중심에는 4분위를 알수없음
- 보통은 x축에 설정한 컬럼의 개별 이산값 별로 Y축 컬럼값의 분포도를 시각화하는 용도로 많이사용
sns.violinplot(x='Pclass',
y='Age',
data=titanic_df)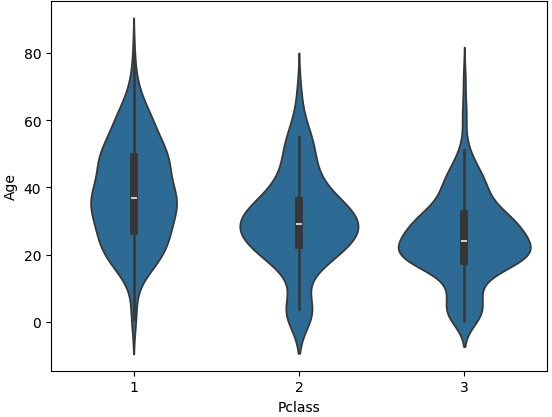
📌 해석 예시
- 1등석/2등석/3등석(Pclass)별로 승객 나이(Age)가 어떤 형태로 분포하는지 보여줍니다.
- 단순 평균만 보는 barplot보다 **“어떤 나이대가 많고, 퍼짐이 얼마나 큰지”**를 더 잘 보여줍니다.
2️⃣ Subplots로 여러 Countplot 한 번에 그리기
✅ 개념/목적
분석 초기에는 보통 범주형 컬럼들이 여러 개 있습니다.
- Survived
- Pclass
- Sex
- Age_cat
이것들을 하나씩 그리면 번거롭고 흐름이 끊기기 때문에, subplots로 한 화면에 배치합니다.
fig, axs = plt.subplots(nrows=2,
ncols=3,
figsize=(12,4))
#subplots를 이용하여 주요 카테고리 성 컬럼 건수 시각화하기
cat_columns = ['Survived', 'Pclass', 'Sex', 'Age_cat']
for index, column in enumerate(cat_columns):
print(index, column)
fig, axs = plt.subplots(nrows=1, ncols=len(cat_columns), figsize=(16, 4))
for index, column in enumerate(cat_columns):
print('index:', index)
# seaborn의 Axes 레벨 function들은 ax인자로 subplots의 어느 Axes에 위치할지 설정.
sns.countplot(x=column, data=titanic_df, ax=axs[index])
if index == 3:
# plt.xticks(rotation=90)으로 간단하게 할수 있지만 Axes 객체를 직접 이용할 경우 API가 상대적으로 복잡.
axs[index].set_xticklabels(axs[index].get_xticklabels(), rotation=90)
✅ 핵심 포인트
- seaborn의 countplot, barplot, violinplot 같은 함수는 Axes-level 함수라서
ax=axs[index]로 “어느 칸에 그릴지” 지정할 수 있습니다. - Age_cat처럼 값이 길거나 많으면 tick이 겹치므로 rotation=90이 필요합니다
3️⃣ Survived 기준으로 분포 비교하기 (Violin + Histogram 동시 비교)
✅ 개념/목적
생존 여부(Survived)에 따라:
- 나이(Age)
- 요금(Fare)
- 동승 형제/배우자(SibSp)
- 동승 부모/자녀(Parch)
이런 연속형 값들의 분포가 어떻게 달라지는지 확인하는 것은 매우 중요한 EDA입니다.
요청하신 방식은 다음처럼 “한 번에” 비교합니다.
- 왼쪽: Survived(0/1)별 Violin plot
- 오른쪽: Survived 0/1 두 분포를 Histogram으로 겹쳐 비교
subplots를 이용하여 여러 연속형 컬럼값들의 Survived 값에 따른 연속 분포도를 시각화
왼쪽에는 Violin Plot으로
오른쪽에는 Survived가 0일때의 Histogram과 Survived가 1일때의 Histogram을 함께 표현
def show_hist_by_target(df, columns):
cond_1 = (df['Survived'] == 1)
cond_0 = (df['Survived'] == 0)
for column in columns:
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 4))
sns.violinplot(x='Survived', y=column, data=df, ax=axs[0] )
sns.histplot(df[cond_0][column], ax=axs[1], kde=True, label='Survived 0', color='blue')
sns.histplot(df[cond_1][column], ax=axs[1], kde=True, label='Survived 1', color='red')
axs[1].legend()
cont_columns = ['Age', 'Fare', 'SibSp', 'Parch']
show_hist_by_target(titanic_df, cont_columns)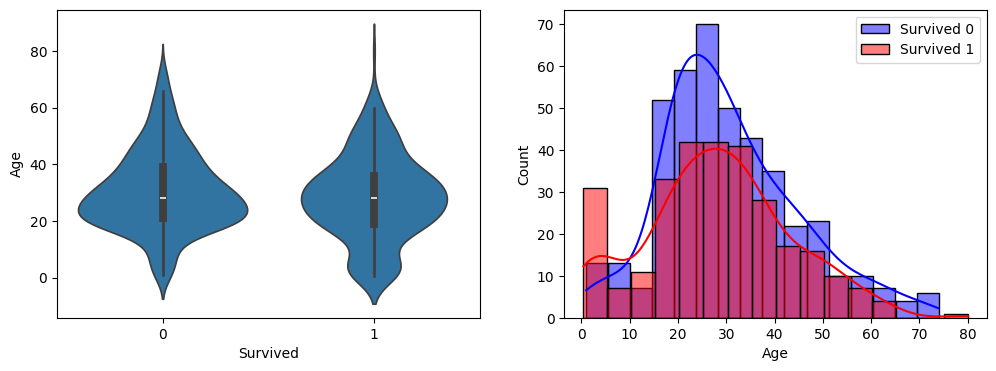



✅ 왜 이렇게 그리나?
- Violin plot은 전체 분포의 윤곽을 강하게 보여줍니다.
- Histogram은 **“어느 구간에 실제로 데이터가 많이 몰렸는지”**를 직관적으로 보여줍니다.
👉 둘을 같이 보면 “형태 + 빈도”를 동시에 확인할 수 있어 EDA가 매우 탄탄해집니다.
4️⃣ Box Plot (박스 플롯)
✅ 개념/목적
Box plot은 **사분위수(4분위)**를 박스 형태로 보여줍니다.
- 박스: Q1 ~ Q3 (중간 50%)
- 중앙선: Median (중앙값)
- 수염: 일반 범위(보통 1.5 IQR)
- 점: 이상치(outlier)
범주별 분포 비교에도 좋습니다.
## Box Plot
- 4분위를 박스 형태로 표현
- x축 값에 이산값을 부여하면 이산값에 따른 box plot을 시각화
sns.boxplot(x='Pclass',
y='Age',
data=titanic_df)
📌 해석 예시
- Pclass별 Age의 중앙값 차이, 퍼짐(변동성), 이상치 존재를 빠르게 확인 가능합니다.
5️⃣ Scatter Plot (산포도)
✅ 개념/목적
Scatter plot은 연속형 X와 연속형 Y 관계를 시각화합니다.
- “나이가 많을수록 요금이 비싼가?”
- “특정 클래스에서 요금이 어떻게 분포하는가?”
같은 관계를 보는 데 적합합니다.
# scatter plot : 산포도로서 X와 Y축에 보통 연속형 값을 시각화. hue, style등을 통해 breakdown 정보를 표출할 수 있습니다.
sns.scatterplot(x='Age', y='Fare', data=titanic_df)
sns.scatterplot(x='Age', y='Fare', data=titanic_df, hue='Pclass')

✅ hue의 의미
hue='Pclass'를 주면
- 같은 산점도 위에 Pclass별로 색이 나뉘어
- “관계가 그룹마다 다른지”를 더 명확히 볼 수 있습니다.
6️⃣ 상관 HeatMap (Correlation Heatmap)
✅ 개념/목적
상관관계는 “변수들 간 선형 관계 강도”를 숫자(-1~1)로 표현합니다.
- 1에 가까울수록 양의 상관
- -1에 가까울수록 음의 상관
- 0이면 선형 상관 거의 없음
Heatmap은 이를 한 번에 “그림”으로 보여줍니다.
# 상관 HeatMap
- 컬럼간의 상관도를 HeatMap형태로 표현
titanic_df.corr(numeric_only=True)
### 상관 Heatmap
plt.figure(figsize=(8, 8))
# DataFrame의 corr()은 숫자형 값만 상관도를 구함.
corr = titanic_df.corr(numeric_only=True)
sns.heatmap(corr, annot=True, fmt='.1f', linewidths=0.5, cmap='YlGnBu')
#sns.heatmap(corr, annot=True, fmt='.2g', cbar=True, linewidths=0.5, cmap='YlGnBu')

✅ 핵심 포인트
- corr(numeric_only=True)는 숫자형 컬럼만 상관을 계산합니다.
- annot=True로 숫자까지 같이 표시되어 해석이 쉬워집니다.
- fmt='.1f'는 소수 1자리로 표현합니다.
이번 파트에서 핵심은 다음입니다.
- Violin plot은 범주별 연속형 분포 비교에 강력합니다.
- Box plot은 사분위수 기반으로 분포를 요약하고 이상치를 확인하는 데 좋습니다.
- Subplots + ax를 쓰면 여러 그래프를 한 번에 배치해 EDA 속도가 빨라집니다.
- Scatterplot은 변수 간 관계를, Heatmap은 상관 구조를 빠르게 파악하는 데 유용합니다.
반응형
'Programming' 카테고리의 다른 글
| Seaborn countplot & barplot 완전 정리 1 | 범주형 데이터 시각화 핵심 가이드 (0) | 2026.02.15 |
|---|---|
| Seaborn 차트 유형 완전 정리 | Histogram, Violin, Bar, Scatter, Line Plot 한 번에 이해하기 (0) | 2026.02.15 |
| Matplotlib 여러 Plot 한 Axes에 그리기 & Subplots 완전 정리 (0) | 2026.02.15 |
| Python Visualization Library 완전 정리 : Matplotlib (0) | 2026.02.15 |
| 데이터 시각화 핵심 개념 한 번에 정리 (0) | 2026.02.15 |