
반응형

📌 개요
데이터 분석에서 범주형 변수(Category Data)는 매우 자주 등장합니다.
- 좌석 등급
- 성별
- 연령대
- 제품 카테고리
이러한 범주형 데이터를 시각화할 때 가장 많이 사용하는 함수가 바로:
- countplot()
- barplot()
이번 글에서는 Titanic 데이터를 활용하여
- countplot의 의미
- barplot의 평균/총합 표현
- confidence interval 제거
- hue를 활용한 그룹 비교
- stackedbar를 흉내 낸 방식
까지 모두 정리합니다.
1️⃣ countplot : 범주별 건수 표현
countplot은 **카테고리 값의 빈도수(건수)**를 표현합니다.
- X축: 범주형 변수
- Y축: 해당 범주의 개수
#countplot : 카테고리 값에 대한 건수를 표현 , x축이 카테고리값, y축이 해당 카테고리값에대한 건수
sns.countplot(x='Pclass',
data=titanic_df)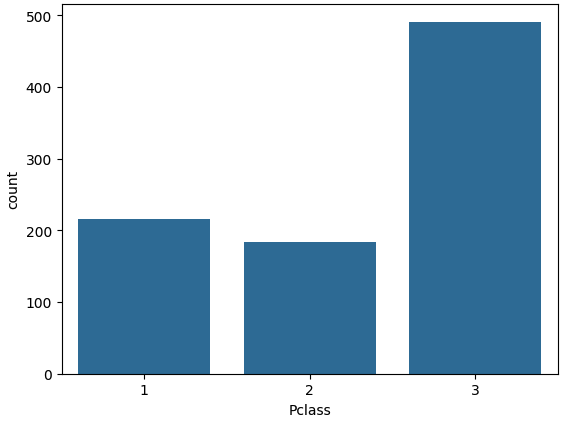
📌 해석
- Pclass(객실 등급)별 승객 수를 보여줍니다.
- 내부적으로 value_counts()를 시각화한 것과 같습니다.
👉 범주형 변수의 분포 확인에 사용합니다.
2️⃣ barplot : 범주형 X + 연속형 Y
barplot은 단순 건수가 아니라
**범주별 연속형 값의 집계값(기본은 평균)**을 보여줍니다.
#barplot : x축은 이산값(주로 category값), y축은 연속값y값의 평균/총합)을 표현
plt.figure(figsize=(10,6))
#자동으로 xlael, ylabel을 x입력값 y입력값으로 설정
sns.barplot(x='Pclass',
y='Survived',
data=titanic_df)
📌 해석
- Pclass별 생존 확률 평균을 보여줍니다.
- Survived는 0/1이므로 평균은 곧 생존율입니다.
👉 평균 기반 집계 시각화에 적합합니다.
3️⃣ Confidence Interval 제거
Seaborn의 barplot은 기본적으로 95% 신뢰구간을 표시합니다.
이를 제거하려면 ci=None을 사용합니다.
#confidence interval 없앰
sns.barplot(x='Pclass',
y='Survived',
data=titanic_df,
ci=None,
color='green')📌 신뢰구간을 제거하면 더 깔끔한 그래프를 얻을 수 있습니다.
4️⃣ 평균 대신 총합 표현
barplot은 기본적으로 평균을 사용하지만
estimator 파라미터를 변경하면 다른 집계 함수도 가능합니다.
#confidence interval 없에고 평균이아닌 총합으로 표현
sns.barplot(x='Pclass',
y='Survived',
data=titanic_df,
ci=None,
color='green',
estimator=sum)#default = average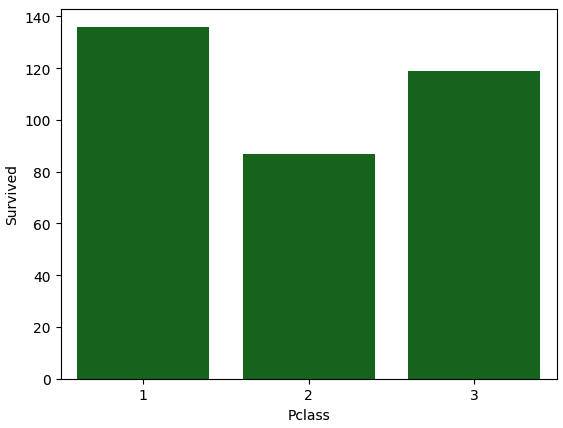
📌 여기서는 평균이 아니라 총 생존자 수를 표현합니다.
👉 estimator 기본값은 np.mean입니다.
5️⃣ hue를 이용한 세분화
hue를 사용하면 하나의 범주를 다시 다른 범주로 나누어 시각화할 수 있습니다.
#barplot에서 hue를 이용하여 x값을 특정 컬럼별로 세분화하여 시각화
sns.barplot(x='Pclass',
y='Age',
hue='Sex',
data=titanic_df)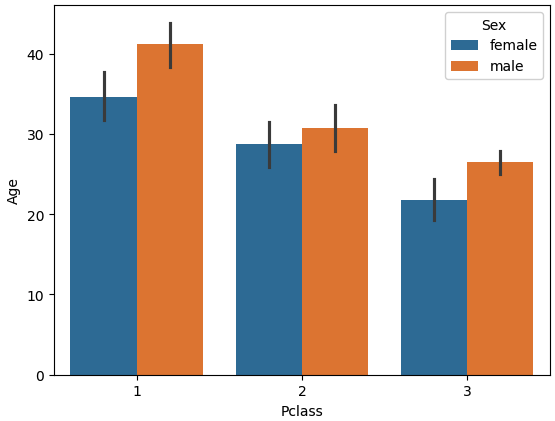
📌 해석
- Pclass별 평균 나이를 성별로 나누어 표현합니다.
👉 범주형 변수 2개를 동시에 비교할 수 있습니다.
6️⃣ stacked bar를 흉내 낸 방식
Seaborn은 기본적으로 stacked bar를 지원하지 않습니다.
하지만 아래처럼 2번 그려서 흉내낼 수 있습니다.
#stackedbar 를 흉내 냈으나 stackedbar라고 할수없음
bar1 = sns.barplot(x='Pclass',
y='Age',
data=titanic_df[titanic_df['Sex']=='male'],
color='darkblue')
bar2 = sns.barplot(x='Pclass',
y='Age',
data=titanic_df[titanic_df['Sex']=='female'],
color='lightblue')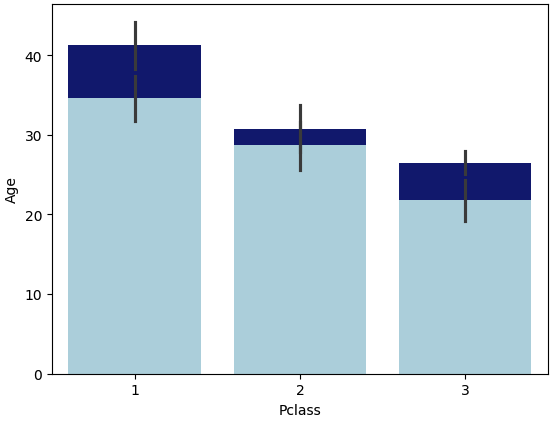
📌 실제 stacked bar는 아니며, 단순히 겹쳐서 그린 것입니다.
7️⃣ Pclass + Sex + Survived 분석
#pclass가 x값 Survived가 y축값 hue파라미터로 sex로 설정 후 개별 pclass값 별로 sex에 따른 survived평균값 구함
sns.barplot(x='Pclass',
y='Survived',
hue='Sex',
data=titanic_df)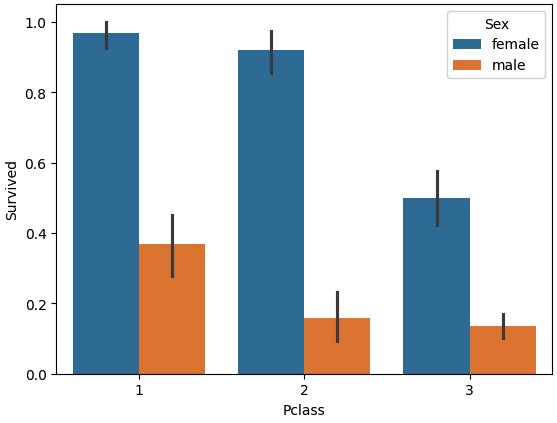
📌 해석
- 1등석 여성의 생존율이 매우 높음을 확인할 수 있습니다.
- 성별과 객실 등급이 생존에 큰 영향을 줍니다.
8️⃣ 연령대별 생존율
plt.figure(figsize=(10, 4))
order_columns = ['Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Elderly']
sns.barplot(x='Age_cat', y='Survived', hue='Sex', data=titanic_df, order=order_columns)📌 order를 지정하면 원하는 순서로 정렬할 수 있습니다.
9️⃣ Sex 중심 분석
sns.barplot(x='Sex', y='Survived', hue='Age_cat', data=titanic_df)
📌 해석
- 여성의 생존율이 전반적으로 높습니다.
- 어린 연령대의 생존율이 상대적으로 높습니다.
🎯 정리
| 함수 | 의미 | 사용 목적 |
| countplot | 범주별 개수 | 분포 확인 |
| barplot | 범주별 평균 | 집계 비교 |
| hue | 그룹 세분화 | 다중 범주 비교 |
| estimator | 집계 함수 변경 | 평균/합계 등 변경 |
| ci=None | 신뢰구간 제거 | 깔끔한 시각화 |
📌 핵심 포인트
- countplot → 단순 빈도
- barplot → 집계값 표현 (기본 평균)
- estimator 변경 가능
- hue로 다차원 분석 가능
- stacked bar는 기본 지원하지 않음
반응형
'Programming' 카테고리의 다른 글
| Seaborn 분포 시각화 완전 정리 2 | Violin/Box/Scatter/Heatmap + Subplots 실전 (0) | 2026.02.15 |
|---|---|
| Seaborn 차트 유형 완전 정리 | Histogram, Violin, Bar, Scatter, Line Plot 한 번에 이해하기 (0) | 2026.02.15 |
| Matplotlib 여러 Plot 한 Axes에 그리기 & Subplots 완전 정리 (0) | 2026.02.15 |
| Python Visualization Library 완전 정리 : Matplotlib (0) | 2026.02.15 |
| 데이터 시각화 핵심 개념 한 번에 정리 (0) | 2026.02.15 |