
반응형

1. LinearRegression 클래스 개요
LinearRegression 클래스는 규제를 적용하지 않은 기본 선형 회귀 모델입니다.
사이킷런에서는 이 모델을 OLS(Ordinary Least Squares) 방식으로 구현합니다.
OLS의 핵심 목적은 다음과 같습니다.
예측값과 실제값의 차이(잔차, Residual)의 제곱합인
RSS(Residual Sum of Squares) 를 최소화하는 회귀 계수 WW를 찾는 것
모델 학습이 완료되면 다음 정보가 자동으로 저장됩니다.
- coef_ : 각 피처에 대한 회귀 계수
- intercept_ : 절편 값
2. 선형 회귀의 다중 공선성 문제
선형 회귀는 입력 피처 간 독립성에 매우 민감합니다.
다중 공선성이란?
- 피처들 간 상관관계가 매우 높은 경우
- 회귀 계수의 분산이 커짐
- 데이터가 조금만 바뀌어도 예측 결과가 크게 흔들림
일반적인 해결 방법
- 상관관계가 높은 피처 제거
- 핵심 피처만 선택
- Ridge, Lasso, ElasticNet과 같은 규제 모델 사용
3. 회귀 평가 지표 정리
회귀 모델은 실제값 − 예측값(오차) 기반으로 평가합니다.
- MAE
실제값과 예측값의 차이를 절대값으로 변환 후 평균 - MSE
오차를 제곱하여 평균 (큰 오차에 민감) - RMSE
MSE에 루트를 씌운 값
→ 큰 오차에 더 큰 패널티 부여 - MSLE / RMSLE
로그 기반 오차 지표
→ 타깃 값이 큰 경우 오류 왜곡 완화 - R² (결정계수)
실제 값 분산 대비 예측 분산 비율
→ 1에 가까울수록 예측 성능 우수
4. LinearRegression으로 보스턴 주택 가격 예측
4.1 데이터 로딩 및 확인
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
# 컬럼명 정의
column_list = [
'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM',
'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B',
'LSTAT', 'PRICE'
]
# 보스턴 주택 데이터 로딩
bostonDF = pd.read_csv(
'./bostondata/housing.csv',
header=None,
delimiter=r"\s+",
names=column_list
)
print(f'Boston Housing 데이터 셋 크기 : {bostonDF.shape}')
display(bostonDF.head(3))
4.2 주요 피처와 타깃(PRICE) 간 관계 시각화
# 2행 × 4열 서브플롯 생성
fig, axs = plt.subplots(nrows=2, ncols=4, figsize=(16, 8))
# 가격과 관계가 크다고 알려진 주요 피처 선택
im_features = ['RM', 'ZN', 'INDUS', 'NOX', 'AGE', 'PTRATIO', 'LSTAT', 'RAD']
# 각 피처와 PRICE 간 회귀 관계 시각화
for i, feature in enumerate(im_features):
row = i // 4
col = i % 4
sns.regplot(
x=feature,
y='PRICE',
data=bostonDF,
ax=axs[row, col]
)
plt.tight_layout()
plt.show()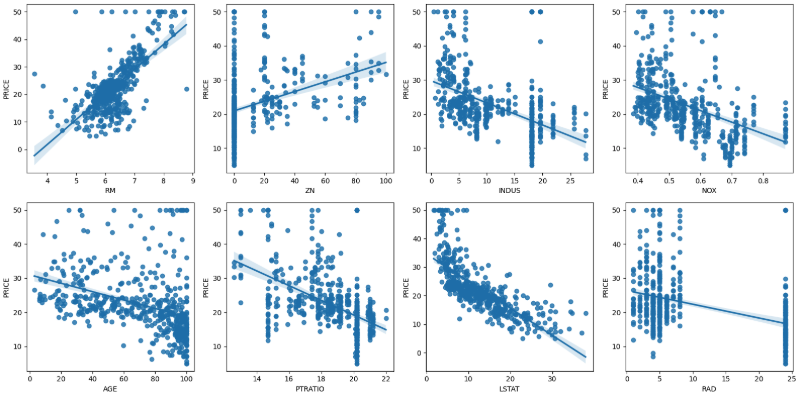
📌 해석 포인트
- RM(방 개수)은 PRICE와 강한 양의 상관관계
- LSTAT(저소득층 비율), NOX는 강한 음의 상관관계
4.3 학습 / 테스트 데이터 분리
from sklearn.model_selection import train_test_split
# 독립 변수(X) / 종속 변수(y) 분리
X_data = bostonDF.drop(['PRICE'], axis=1)
y_target = bostonDF['PRICE']
# 학습 70%, 테스트 30%
X_train, X_test, y_train, y_test = train_test_split(
X_data,
y_target,
test_size=0.3,
random_state=156
)4.4 LinearRegression 모델 학습 및 평가
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 모델 생성 및 학습
lr = LinearRegression()
lr.fit(X_train, y_train)
# 예측
y_preds = lr.predict(X_test)
# 평가 지표 계산
mse = mean_squared_error(y_test, y_preds)
rmse = np.sqrt(mse)
print(f'MSE : {mse}')
print(f'RMSE : {rmse}')
print(f'R2 Score : {r2_score(y_test, y_preds)}')
print(f'절편값(intercept) : {lr.intercept_}')
print(f'회귀계수(coef) : {np.round(lr.coef_, 1)}')4.5 회귀 계수 해석
독립변수(X)가 1단위 변할 때 종속변수(Y)가 평균적으로 얼마나 변하는지를 나타내는 값으로, 두 변수 간의 영향력의 크기와 방향을 나타내는 지표
# 회귀 계수를 Series로 생성 후 정렬
coeff = pd.Series(
data=np.round(lr.coef_, 1),
index=X_data.columns
)
coeff.sort_values(ascending=False)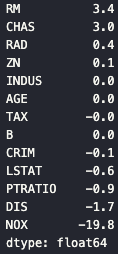
📌 회귀 계수 해석 기준
- 양수(+) : 해당 피처 증가 → PRICE 증가
- 음수(-) : 해당 피처 증가 → PRICE 감소
- 0 근처 : 영향 미미
4.6 교차 검증을 통한 성능 안정성 확인
from sklearn.model_selection import cross_val_score
lr = LinearRegression()
# 5-Fold 교차 검증으로 MSE 계산
neg_mse_scores = cross_val_score(
lr,
X_data,
y_target,
scoring='neg_mean_squared_error',
cv=5
)
# RMSE로 변환
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(f'5 fold 개별 negative MSE scores : {neg_mse_scores}')
print(f'5 fold 개별 RMSE scores : {rmse_scores}')
print(f'5 fold 평균 RMSE : {avg_rmse}')
반응형
'Programming' 카테고리의 다른 글
| 다항 회귀(Polynomial Regression)를 이용한 보스턴 주택가격 예측 (1) | 2026.01.05 |
|---|---|
| 다항 회귀(Polynomial Regression)의 이해와 실습 (0) | 2026.01.05 |
| LinearRegression 클래스와 선형 회귀 평가 지표 정리 (0) | 2026.01.02 |
| 경사하강법(Gradient Descent) 이해하기 – 선형 회귀 실습으로 개념 완전 정리 (0) | 2026.01.02 |
| 회귀(Regression)란 무엇인가 – 개념부터 머신러닝까지 (0) | 2026.01.02 |