
반응형

1. 경사하강법(Gradient Descent)이란?
경사하강법(Gradient Descent)은 **비용 함수(Cost Function)**를 최소화하기 위해
모델의 파라미터를 반복적으로 업데이트하는 최적화 알고리즘입니다.
머신러닝 회귀 문제의 핵심 목표는 다음과 같습니다.
예측값과 실제값의 차이(오류)를 최소화하는
**최적의 회귀 계수(W)**를 찾는 것
이때 오류를 수치화한 함수가 바로 **비용 함수(RSS, MSE 등)**이며,
경사하강법은 이 비용 함수가 가장 작아지는 방향으로 파라미터를 이동시키는 방식입니다.
2. 실습 데이터 생성 – y = 4x + 6 + noise
아래 코드는 실제 선형식을 기반으로 노이즈가 포함된 회귀 데이터를 생성합니다.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(0)
# y = 4x + 6 식을 근사 (w1=4, w0=6)
X = 2 * np.random.rand(100,1)
y = 6 + 4 * X + np.random.randn(100,1)
# 시각화
plt.scatter(X, y)
- 실제 정답 계수는 w1 = 4, w0 = 6
- 랜덤 노이즈로 인해 완벽한 직선이 아닌 분포를 가짐
- 경사하강법이 이 계수들을 얼마나 잘 복원하는지 확인하는 것이 목표입니다.
3. 가중치 업데이트 함수 구현
경사하강법의 핵심은 미분을 통해 구한 기울기를 이용해
가중치(w0, w1)를 업데이트하는 것입니다.
def get_weight_updates(w1, w0, X, y, learning_rate=0.01):
N = len(y)
w1_update = np.zeros_like(w1)
w0_update = np.zeros_like(w0)
# 예측값 계산
y_pred = np.dot(X, w1.T) + w0
diff = y - y_pred
# w0 계산을 위한 상수 벡터
w0_factors = np.ones((N,1))
# 경사하강법 업데이트 공식
w1_update = -(2/N) * learning_rate * (np.dot(X.T, diff))
w0_update = -(2/N) * learning_rate * (np.dot(w0_factors.T, diff))
return w1_update, w0_update
핵심 포인트
- (y - y_pred) : 실제값과 예측값의 오차
- -(2/N) : MSE 비용 함수 미분 결과
- learning_rate : 한 번에 이동하는 보폭
4. 배치 경사하강법(Batch Gradient Descent)
전체 데이터를 사용해 반복적으로 가중치를 업데이트합니다.
def gradient_descent_steps(X, y, iters=10000):
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
for ind in range(iters):
w1_update, w0_update = get_weight_updates(w1, w0, X, y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w05. 비용 함수(Cost Function) 정의
비용 함수는 예측 성능을 수치로 평가하는 기준입니다.
여기서는 평균 제곱 오차(MSE)를 사용합니다.
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y - y_pred)) / N
return cost6. 경사하강법 실행 결과 확인
w1, w0 = gradient_descent_steps(X, y, iters=1000)
print(f'w1: {w1[0,0]}')
print(f'w0: {w0[0,0]}')
y_pred = w1[0,0] * X + w0
print(f'Gradient Descent Total cost : {get_cost(y, y_pred)}')출력 결과를 보면 다음을 확인할 수 있습니다.
- w1 ≈ 4
- w0 ≈ 6
- 비용 함수 값이 충분히 작은 값으로 수렴
즉, 경사하강법이 실제 회귀 계수를 잘 찾아냄을 확인할 수 있습니다.
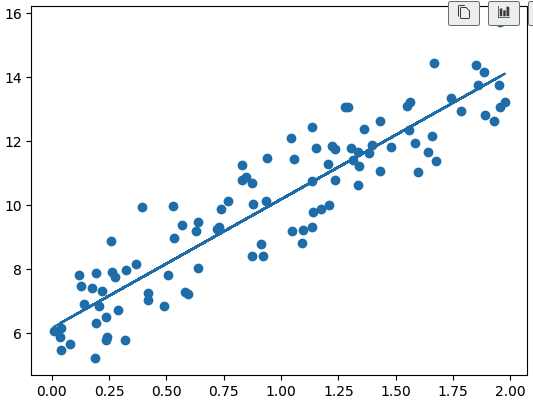
7. 결과 시각화
plt.scatter(X, y)
plt.plot(X, y_pred)
- 산점도 위에 회귀 직선이 잘 맞춰짐
- 초기 랜덤 분포 → 최적의 직선으로 수렴
8. 미니 배치 확률적 경사하강법(SGD)
이번에는 **전체 데이터가 아닌 일부 데이터(batch)**만 사용해 학습합니다.
def stochastic_gradient_descent_steps(X, y, batch_size=10, iters=1000):
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
for ind in range(iters):
np.random.seed(ind)
# 랜덤 배치 추출
stochastic_random_index = np.random.permutation(X.shape[0])
sample_X = X[stochastic_random_index[0:batch_size]]
sample_y = y[stochastic_random_index[0:batch_size]]
w1_update, w0_update = get_weight_updates(
w1, w0, sample_X, sample_y, learning_rate=0.01
)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0
w1, w0 = stochastic_gradient_descent_steps(X, y, batch_size=10, iters=1000)
y_pred = w1[0,0] * X + w0
SGD 특징
- 연산 속도 빠름
- 노이즈로 인해 수렴 경로가 흔들릴 수 있음
- 대용량 데이터에서 매우 유리
9. 정리
- 경사하강법은 비용 함수를 최소화하는 방향으로 파라미터를 반복 업데이트하는 알고리즘입니다.
- 선형 회귀에서 목표는 RSS(MSE)를 최소화하는 회귀 계수 W를 찾는 것입니다.
- 배치 GD는 안정적이고,
- 미니 배치/확률적 GD는 빠르고 확장성이 뛰어납니다.
경사하강법은
선형 회귀 → 로지스틱 회귀 → 신경망 → 딥러닝
모든 학습 알고리즘의 핵심 기반이 되는 개념입니다.
반응형
'Programming' 카테고리의 다른 글
| LinearRegression 클래스와 보스턴 주택 가격 예측 실습 (0) | 2026.01.05 |
|---|---|
| LinearRegression 클래스와 선형 회귀 평가 지표 정리 (0) | 2026.01.02 |
| 회귀(Regression)란 무엇인가 – 개념부터 머신러닝까지 (0) | 2026.01.02 |
| 내용 요약 정리 (Classification · Tree · Ensemble · Feature Engineering) (0) | 2026.01.02 |
| Feature Selection 실전 : 정리모델 성능과 해석력을 동시에 잡는 방법 (0) | 2026.01.01 |