

머신러닝의 분류(Classification) 문제는 가장 기본적이면서도 실무에서 가장 많이 활용되는 영역입니다.
분류란 학습 데이터로 주어진 피처(Feature)와 레이블(Label)을 머신러닝 알고리즘으로 학습하여 모델을 생성하고, 새로운 데이터가 주어졌을 때 미지의 레이블 값을 예측하는 과정를 의미합니다.
대표적인 분류 알고리즘에는 다음과 같은 것들이 있습니다.
- 나이브 베이즈(Naive Bayes)
- 로지스틱 회귀(Logistic Regression)
- 결정트리(Decision Tree)
- 서포트 벡터 머신(SVM)
- 최근접 이웃(KNN)
- 심층 신경망(DNN)
- 여러 모델을 결합한 앙상블(Ensemble)
이 글에서는 그중에서도 가장 직관적이고, 앙상블의 핵심 기반이 되는 결정트리 알고리즘을 중심으로 개념부터 실습, 시각화까지 정리합니다.
1. 결정트리란 무엇인가
결정트리는 데이터에 존재하는 규칙을 학습을 통해 자동으로 찾아내고, 이를 Tree 구조의 If–Else 규칙으로 표현하는 분류 알고리즘입니다.
즉, 사람이 의사결정을 할 때
“이 조건이면 A, 아니면 B”
라고 판단하는 과정을 트리(Tree) 구조로 수학적으로 모델링한 것입니다.
결정트리는 다음과 같은 노드 구조를 가집니다.
- 루트 노드(Root Node): 가장 처음 분기되는 기준
- 규칙 노드(Decision Node): 분기 조건이 적용되는 중간 노드
- 리프 노드(Leaf Node): 최종 분류 결과가 결정되는 노드
2. 결정트리의 핵심: 어떤 기준으로 분할할 것인가
결정트리의 성능은
👉 **“어떤 피처를 기준으로, 어떤 순서로 데이터를 분할하느냐”**에 의해 좌우됩니다.
이를 판단하기 위해 **노드의 균일도(순수도)**를 측정합니다.
(1) 엔트로피(Entropy)와 정보 이득(Information Gain)
- 엔트로피는 혼잡도를 의미합니다.
- 값이 낮을수록 한 클래스에 잘 모여 있는 상태입니다.
정보 이득은 다음과 같이 정의됩니다.
정보 이득 = 기존 엔트로피 − 분할 후 엔트로피
즉, 정보 이득이 높은 피처를 기준으로 분할합니다.
(2) 지니 계수(Gini Index)
- 지니 계수는 불순도를 측정합니다.
- 값이 0에 가까울수록 순수, 1에 가까울수록 불순합니다.
사이킷런의 DecisionTreeClassifier는
👉 **기본적으로 지니 계수(Gini Index)**를 사용합니다.
3. 결정트리의 장점과 단점
✅ 장점
- 직관적이고 해석이 쉽습니다.
- 데이터 스케일링이나 정규화의 영향을 거의 받지 않습니다.
- 전처리가 비교적 적게 필요합니다.
❌ 단점
- 트리를 깊게 만들수록 **과적합(Overfitting)**이 쉽게 발생합니다.
- 학습 데이터에 지나치게 맞춰져 일반화 성능이 저하될 수 있습니다.
이 단점 때문에 결정트리는 단독으로 쓰이기보다는
👉 앙상블 기법의 ‘약한 학습기’로서 더 큰 가치를 가집니다.
4. 결정트리와 앙상블의 관계
앙상블(Ensemble)은
여러 개의 성능이 약한 모델을 결합해 강력한 모델을 만드는 기법입니다.
결정트리는 다음 이유로 앙상블에 매우 적합한 약한 학습기입니다.
- 구조가 단순하고
- 규칙 기반 분기가 명확하며
- 서로 다른 트리를 쉽게 다양화할 수 있기 때문입니다.
대표적인 결정트리 기반 앙상블 모델은 다음과 같습니다.
- 랜덤 포레스트(Random Forest)
- 그래디언트 부스팅(GBM)
- XGBoost
- LightGBM
👉 결정트리의 과적합 성향이 앙상블에서는 오히려 장점으로 작용합니다.
5. 결정트리 주요 하이퍼파라미터 정리
결정트리는 하이퍼파라미터 튜닝이 매우 중요합니다.
(1) max_depth
- 트리의 최대 깊이
- 값이 커질수록 과적합 위험 증가
- 과적합 제어의 핵심 파라미터
(2) max_features
- 분할 시 고려할 최대 피처 수
- 기본값은 None (모든 피처 사용)
- 값을 줄이면 과적합 완화
(3) min_samples_split
- 노드를 분할하기 위한 최소 샘플 수
- 작을수록 더 많은 분기 발생 → 과적합 가능성 증가
- “이 노드를 쪼갤 수 있는가?”에 대한 기준
(4) min_samples_leaf
- 리프 노드가 가져야 할 최소 샘플 수
- 너무 작은 리프 노드 생성을 방지
- 과적합 제어에 매우 효과적
(5) max_leaf_nodes
- 생성 가능한 리프 노드의 최대 개수
- 트리 복잡도 직접 제한
6. 결정트리 모델 시각화 (Graphviz)
결정트리는 시각화가 가능한 몇 안 되는 머신러닝 모델입니다.
6-1. Graphviz 설치 방법
▶ macOS (Homebrew)
brew install graphviz▶ Ubuntu
sudo apt-get install graphviz▶ Windows
- Graphviz 공식 홈페이지에서 설치 파일 다운로드
- 설치 후 환경변수 PATH 설정 필요
6-2. 결정트리 시각화 실습
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import export_graphviz
import graphviz
import warnings
warnings.filterwarnings('ignore')
# 결정트리 모델 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 아이리스 데이터 로딩
iris_data = load_iris()
# 학습/테스트 분리
X_train, X_test, y_train, y_test = train_test_split(
iris_data.data,
iris_data.target,
test_size=0.2,
random_state=11
)
# 모델 학습
dt_clf.fit(X_train, y_train)
# DOT 파일 생성
export_graphviz(
dt_clf,
out_file="tree.dot",
class_names=iris_data.target_names,
feature_names=iris_data.feature_names,
impurity=True,
filled=True
)
# Graphviz로 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)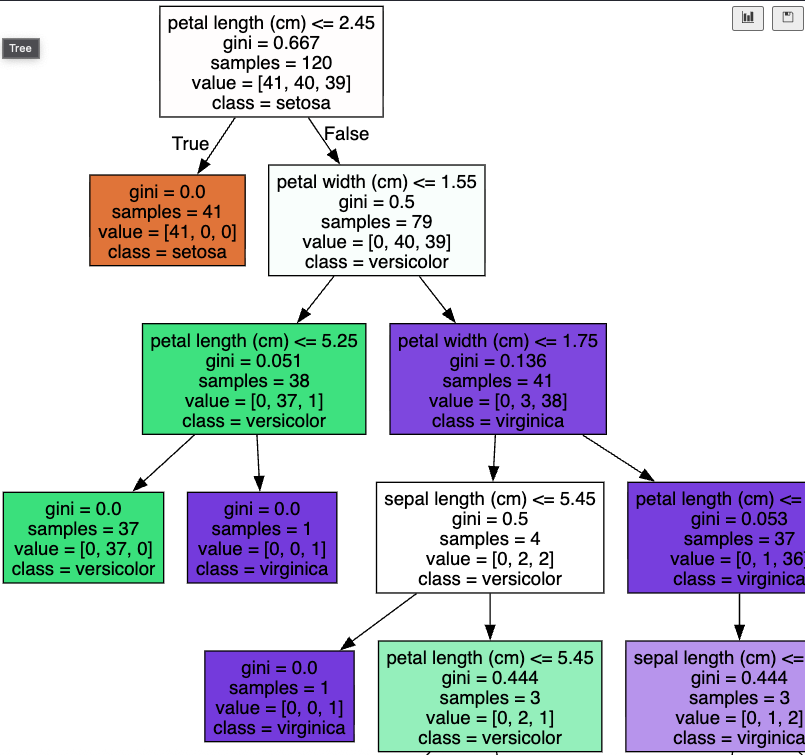
결정트리는
- 머신러닝 입문자가 가장 먼저 이해하기 좋은 알고리즘이며
- 앙상블 모델의 핵심 기반이 되는 매우 중요한 알고리즘입니다.
핵심을 정리하면 다음과 같습니다.
- 결정트리는 규칙 기반 분류 모델입니다.
- 해석력이 뛰어나지만 과적합에 취약합니다.
- 하이퍼파라미터 튜닝이 성능을 좌우합니다.
- 앙상블에서는 결정트리의 단점이 오히려 장점이 됩니다.
'Programming' 카테고리의 다른 글
| 앙상블 학습(Ensemble Learning) 완전 정리 1편: 개념 이해와 보팅(Voting) 실습 (0) | 2025.12.17 |
|---|---|
| 결정트리 속성 중요도(Feature Importance)와 과적합(Overfitting) 쉽게 이해하기 (0) | 2025.12.16 |
| [분류 성능 평가지표 4편] 피마 인디언 당뇨병 예측 실습으로 이해하는 분류 평가의 모든 것 (2) | 2025.12.13 |
| [분류 성능 평가지표 3편] F1 Score·ROC-AUC로 이진 분류 성능 완성하기 (0) | 2025.12.13 |
| [분류 성능 평가지표 2편] 오차행렬·정밀도·재현율 그리고 트레이드오프 (0) | 2025.12.13 |