

1편에서는 **정확도(Accuracy)**가 왜 이진 분류에서 위험한 지표가 될 수 있는지를 살펴보았습니다.
특히 불균형한 레이블 분포에서는 아무 생각 없이 예측해도 높은 정확도가 나올 수 있다는 점을 확인했습니다.
그렇다면 질문이 생깁니다.
“얼마나 많이 틀렸는지”뿐만 아니라
“어떤 방식으로 틀렸는지”를 알 수는 없을까?
이 질문에 대한 답이 바로 **오차행렬(Confusion Matrix)**이며,
이를 기반으로 계산되는 지표가 **정밀도(Precision)**와 **재현율(Recall)**입니다.
이번 2편에서는
- 오차행렬의 구조와 해석 방법
- 정밀도와 재현율의 정의
- 두 지표의 트레이드오프 관계
- 분류 결정 임계값(Threshold)을 조정했을 때의 변화
를 코드와 함께 차근차근 설명합니다.
1. 오차행렬(Confusion Matrix)이란?
**오차행렬(Confusion Matrix)**은
이진 분류 모델이 어떤 유형의 예측을 얼마나 했는지를 한눈에 보여주는 표입니다.
정확도가 단순히 “맞았는가/틀렸는가”만 알려준다면,
오차행렬은 다음을 모두 구분해 줍니다.
- 실제 음성(Negative)을 음성으로 예측했는가
- 실제 음성을 양성으로 잘못 예측했는가
- 실제 양성을 음성으로 놓쳤는가
- 실제 양성을 양성으로 정확히 맞혔는가
2. 오차행렬 구성 요소 (TN, FP, FN, TP)
앞 알파벳 = 실제값
뒤 알파벳 = 예측값
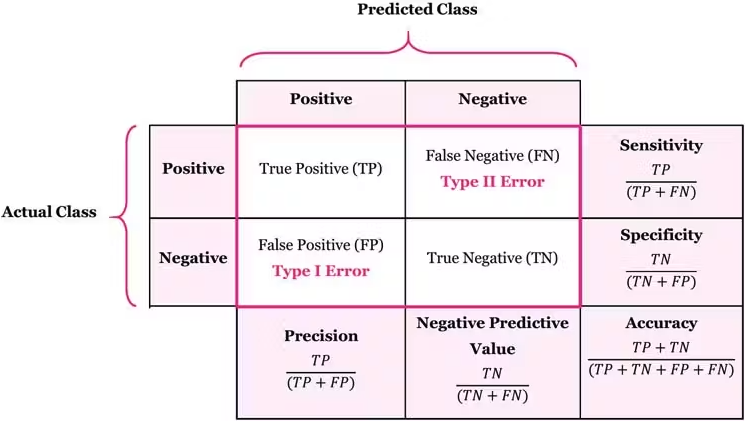
| TN (True Negative) | 실제 0, 예측 0 |
| FP (False Positive) | 실제 0, 예측 1 |
| FN (False Negative) | 실제 1, 예측 0 |
| TP (True Positive) | 실제 1, 예측 1 |
👉 **대각선(TN → TP)**으로 값이 커질수록 모델이 잘 맞추고 있다고 이해하면 됩니다.
보통은 TN에서 TP로 대각선 방향으로 외우는 것이 가장 쉽습니다.
3. 오차행렬 예제: 아무 것도 안 맞힌 모델
1편에서 사용했던 모든 값을 0으로 예측하는 가짜 분류기 결과를 다시 확인해봅니다.
from sklearn.metrics import confusion_matrix
# 실제 값(y_test)과 예측 값(fakepred)으로 오차행렬 생성
confusion_matrix(y_test, fakepred)
[[405 0]
[ 45 0]]해석
- TN = 405 → 실제 0을 0으로 잘 예측
- FN = 45 → 실제 1을 전부 0으로 잘못 예측
- TP = 0 → 단 하나의 Positive도 맞히지 못함
👉 **정확도는 높았지만, 실제로는 “양성 탐지 능력이 0인 모델”**임을 오차행렬이 명확히 보여줍니다.
4. 정밀도(Precision)와 재현율(Recall)
이제 오차행렬을 기반으로 계산되는 핵심 지표 두 가지를 살펴봅니다.
4-1. 정밀도(Precision)
정밀도 = TP / (TP + FP)
- 모델이 Positive(1)라고 예측한 것들 중
- 실제로 Positive인 비율
👉 예측값 기준 지표입니다.
“Positive라고 말한 것 중에서, 얼마나 맞았는가?”
4-2. 재현율(Recall)
재현율 = TP / (TP + FN)
- 실제 Positive 데이터 중에서
- 모델이 Positive로 맞힌 비율
👉 실제값 기준 지표입니다.
“실제로 중요한 대상 중에서, 얼마나 놓치지 않았는가?”
4-3. 사이킷런으로 계산
from sklearn.metrics import accuracy_score, precision_score, recall_score
print(f"정밀도 : {precision_score(y_test, fakepred)}")
print(f"재현율 : {recall_score(y_test, fakepred)}")👉 TP가 0이기 때문에 정밀도와 재현율 모두 0이 됩니다.
정확도 하나만 보면 절대 알 수 없는 사실입니다.
5. 평가 지표를 한 번에 출력하는 함수
실무에서는 정확도·정밀도·재현율·오차행렬을 항상 함께 확인합니다.
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score
def get_clf_eval(y_test, pred):
"""
분류 성능 평가 지표를 한 번에 출력하는 함수
"""
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print("오차행렬")
print(confusion)
print(f"정확도 : {accuracy}")
print(f"정밀도 : {precision}")
print(f"재현율 : {recall}")6. 타이타닉 데이터 + 로지스틱 회귀 평가
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 데이터 로딩
titanic_df = pd.read_csv('./titanic/titanic_train.csv')
# 타깃과 피처 분리
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop("Survived", axis=1)
# 전처리
X_titanic_df = transform_features(X_titanic_df)
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
X_titanic_df, y_titanic_df, test_size=0.2, random_state=0
)
# 로지스틱 회귀 학습
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train, y_train)
# 예측
pred = lr_clf.predict(X_test)
# 성능 평가
get_clf_eval(y_test, pred)
오차행렬 [[93 17]
[20 49]]
정확도 : 0.7933
정밀도 : 0.7424
재현율 : 0.71017. 정밀도–재현율 트레이드오프(Trade-off)
7-1. 왜 트레이드오프가 발생하는가
- 재현율을 높이려면 → Positive로 더 많이 예측해야 함
- 그러면 FP가 늘어나 → 정밀도 하락
- 정밀도를 높이려면 → Positive 판정을 엄격하게
- 그러면 FN 증가 → 재현율 하락
👉 두 지표는 서로 반비례 관계를 가집니다.
7-2. 업무별 중요 지표 예시
| 암 진단, 금융 사기 탐지 | 재현율 |
| 스팸 메일 필터링 | 정밀도 |
8. 분류 결정 임계값(Threshold) 조정
임계값은 “확률을 기준으로 1로 볼지, 0으로 볼지 결정하는 기준선” 입니다. 보통 기본값은 0.5 입니다.
기본적으로 사이킷런 분류 모델은
- 확률 ≥ 0.5 → Positive
- 확률 < 0.5 → Negative로 판단합니다.
- 이 **0.5를 임계값(Threshold)**이라고 합니다.
| 0.91 | ≥ 0.5 | 1 |
| 0.67 | ≥ 0.5 | 1 |
| 0.42 | < 0.5 | 0 |
| 0.18 | < 0.5 | 0 |
임계값을 바꾸면 무엇이 달라지는가?
| 높음 (0.7~0.9) | 보수적 → 정밀도↑, 재현율↓ |
| 낮음 (0.2~0.3) | 공격적 → 재현율↑, 정밀도↓ |
즉,
임계값 = 정밀도와 재현율의 균형 조절기
8-1. predict_proba() 확인
# 각 클래스에 속할 확률 반환
pred_proba = lr_clf.predict_proba(X_test)
print(f"predict_proba shape : {pred_proba.shape}")
print("앞 3개 샘플")
print(pred_proba[:3])
- 왼쪽 열: 0일 확률
- 오른쪽 열: 1일 확률
8-2. Binarizer로 임계값 조정
from sklearn.preprocessing import Binarizer
# Positive 클래스 확률만 추출
pred_proba_1 = pred_proba[:, 1].reshape(-1, 1)
# 기본 임계값 0.5
binarizer = Binarizer(threshold=0.5)
custom_pred = binarizer.fit_transform(pred_proba_1)
get_clf_eval(y_test, custom_pred)
# 임계값을 0.4로 낮추기
binarizer = Binarizer(threshold=0.4)
custom_pred = binarizer.fit_transform(pred_proba_1)
get_clf_eval(y_test, custom_pred)
👉 임계값을 낮추면 재현율은 증가, 정밀도는 감소하는 현상을 확인할 수 있습니다.
9. 여러 임계값에서 성능 비교
from sklearn.metrics import f1_score, roc_auc_score
def get_eval_by_threshold(y_test, pred_proba_c1, thresholds):
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold)
custom_pred = binarizer.fit_transform(pred_proba_c1)
print(f"\n임계값 : {custom_threshold}")
get_clf_eval(y_test, custom_pred)
thresholds = [0.3,0.4,0.5,0.6,0.7]
get_eval_by_threshold(y_test, pred_proba_1, thresholds)
10. precision_recall_curve() 시각화
precision_recall_curve() 는 무엇을 위한 것인가?
임계값을 계속 바꿔가며 정밀도와 재현율의 변화를 한 번에 계산하는 함수

from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
def precision_recall_curve_plot(y_test, pred_proba_c1):
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_c1)
plt.figure(figsize=(8,6))
plt.plot(thresholds, precisions[:-1], '--', label='Precision')
plt.plot(thresholds, recalls[:-1], label='Recall')
plt.xlabel("Threshold")
plt.ylabel("Score")
plt.legend()
plt.grid()
plt.show()
precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:,1])이번 2편에서는 정확도를 보완하는 핵심 지표들을 배웠습니다.
- 오차행렬은 “어떻게 틀렸는지”를 보여줍니다.
- 정밀도는 예측 기준, 재현율은 실제 기준 지표입니다.
- 두 지표는 트레이드오프 관계입니다.
- 임계값 조정을 통해 업무 목적에 맞는 균형점을 찾을 수 있습니다.
다음 3편에서는
- F1 Score
- ROC 곡선과 AUC
를 통해 정밀도와 재현율을 하나의 지표로 보는 방법과
모델의 전반적인 분류 능력을 평가하는 방법을 다루겠습니다.
'Programming' 카테고리의 다른 글
| [분류 성능 평가지표 4편] 피마 인디언 당뇨병 예측 실습으로 이해하는 분류 평가의 모든 것 (2) | 2025.12.13 |
|---|---|
| [분류 성능 평가지표 3편] F1 Score·ROC-AUC로 이진 분류 성능 완성하기 (0) | 2025.12.13 |
| [분류 성능 평가지표 1편] 정확도(Accuracy)는 왜 조심해서 봐야 할까? (0) | 2025.12.13 |
| ChromeDriver 버전 불일치로 발생하는 SessionNotCreatedException 해결 방법(undetected-chromedriver 기준) (0) | 2025.12.10 |
| [6편] 타이타닉 생존 예측 풀 파이프라인: 전처리부터 교차검증·튜닝까지 한 번에 정리하기 (0) | 2025.12.10 |