

1~5편에서 우리는 다음 내용을 단계별로 정리했습니다.
- 1편: 사이킷런과 머신러닝 기본 개념(피처, 레이블, 지도학습 등)
- 2편: 학습/테스트 데이터 분리, 모델 학습, 예측, 평가
- 3편: K-Fold, Stratified K-Fold 교차검증
- 4편: cross_val_score(), GridSearchCV를 이용한 자동 교차검증과 하이퍼파라미터 튜닝
- 5편: 데이터 인코딩(Label/One-Hot)과 스케일링(StandardScaler, MinMaxScaler)
이번 6편은 이 모든 내용을 실제 프로젝트에 적용하는 종합 실습편입니다.
가장 유명한 예제 데이터셋인 타이타닉(Titanic) 생존 예측을 가지고
- 데이터 로딩 & EDA
- 전처리(결측값 처리, 불필요 피처 제거, 인코딩)
- 세 가지 모델 학습 및 비교(결정트리, 랜덤포레스트, 로지스틱 회귀)
- K-Fold 교차검증 직접 구현
- cross_val_score() 적용
- GridSearchCV()로 하이퍼파라미터 튜닝 및 최종 평가
까지 전 과정을 하나의 파이프라인으로 연결해 보겠습니다.
코드는 모두 줄 단위로 이해할 수 있도록 주석을 자세히 달았습니다.
1. 타이타닉 데이터 로딩 및 기본 정보 확인
# -----------------------------------------------------------
# 1. 라이브러리 및 데이터 로딩
# -----------------------------------------------------------
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 시각화 스타일 설정 (선택 사항)
sns.set(style="whitegrid")
# 타이타닉 학습용 데이터 로딩
titanic_df = pd.read_csv("./titanic/titanic_train.csv")
# 상위 5개 행 확인
titanic_df.head(5)
# -----------------------------------------------------------
# 데이터 정보 및 기초 통계 확인
# -----------------------------------------------------------
# 각 컬럼의 타입, Non-Null 개수, 메모리 사용량 등 확인
titanic_df.info()
# 수치형 컬럼에 대한 기본 통계량(평균, 분산, 최소/최대 등) 확인
titanic_df.describe()


2. 결측값 처리 및 간단 EDA
2-1. 결측값(Null) 처리
# -----------------------------------------------------------
# 2. 결측값(Null) 처리
# -----------------------------------------------------------
# Age 결측값: 평균 나이로 대체
titanic_df["Age"].fillna(titanic_df["Age"].mean(), inplace=True)
# Cabin 결측값: 'N'이라는 임의의 카테고리로 대체 (객실 정보 없음)
titanic_df["Cabin"].fillna("N", inplace=True)
# Embarked 결측값: 'N'이라는 카테고리로 대체
titanic_df["Embarked"].fillna("N", inplace=True)
# 각 컬럼별 결측값 개수 확인
print("컬럼별 Null 개수:\n", titanic_df.isnull().sum())
2-2. 주요 범주형 컬럼 EDA
# -----------------------------------------------------------
# 3. 주요 범주형 컬럼 EDA
# -----------------------------------------------------------
# object 타입(문자열) 컬럼 목록 출력
obj_cols = titanic_df.dtypes[titanic_df.dtypes == "object"].index.tolist()
print("문자열 컬럼 목록:", obj_cols)
# 성별 분포
print("\n[Sex 값 분포]")
print(titanic_df["Sex"].value_counts())
# 객실(Cabin) 값 분포
print("\n[Cabin 값 분포]")
print(titanic_df["Cabin"].value_counts())
# 승선 항구(Embarked) 값 분포
print("\n[Embarked 값 분포]")
print(titanic_df["Embarked"].value_counts())
# 성별에 따른 생존 인원 수
print("\n[성별에 따른 생존 여부]")
print(titanic_df.groupby(["Sex", "Survived"])["Survived"].count())

# -----------------------------------------------------------
# 4. Pclass, Sex에 따른 생존율 시각화
# -----------------------------------------------------------
plt.figure(figsize=(8, 4))
sns.barplot(
x="Pclass", # 좌석 등급(1, 2, 3등석)
y="Survived", # 생존 여부(0/1)
hue="Sex", # 성별에 따라 색 구분
data=titanic_df
)
plt.title("Pclass와 성별에 따른 생존율")
plt.show()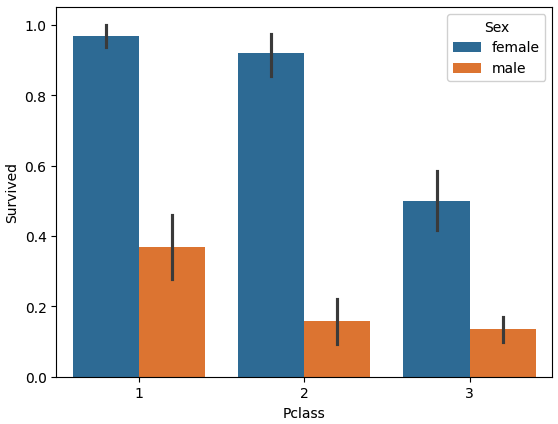
2-3. Age를 범주형 구간으로 나누어 보기(Feature Engineering 예시)
# -----------------------------------------------------------
# 5. 나이(Age)에 따른 생존율 시각화
# - 나이를 구간(category)으로 나누는 함수 정의
# -----------------------------------------------------------
def get_category(x):
"""나이 값을 카테고리 구간으로 변환하는 함수"""
if x <= -1:
return "Unknown"
elif x <= 5:
return "Baby"
elif x <= 12:
return "Child"
elif x <= 25:
return "Student"
elif x <= 35:
return "Young Adult"
elif x <= 60:
return "Adult"
else:
return "Eldery"
# 시각화용 카테고리 순서 정의
group_names = ["Unknown", "Baby", "Child", "Student", "Young Adult", "Adult", "Eldery"]
# Age를 카테고리로 변환한 새로운 컬럼 생성
titanic_df["Age_cat"] = titanic_df["Age"].apply(lambda x: get_category(x))
plt.figure(figsize=(10, 6))
sns.barplot(
x="Age_cat",
y="Survived",
hue="Sex",
data=titanic_df,
order=group_names
)
plt.title("연령대 & 성별에 따른 생존율")
plt.show()
# 시각화용으로만 사용했으므로 제거
titanic_df.drop("Age_cat", axis=1, inplace=True)
3. 전처리 함수화: 결측값 처리 + 불필요 컬럼 제거 + 레이블 인코딩
타이타닉 데이터는 학습/검증/추론 단계에서 여러 번 전처리가 필요하므로,
반복되는 작업을 함수로 묶어서 재사용 가능한 파이프라인으로 만들겠습니다.
# -----------------------------------------------------------
# 6. 전처리 파이프라인 함수 정의
# - fillna() : 결측값 처리
# - drop_features() : 불필요 피처 제거
# - format_features() : 문자열 컬럼 레이블 인코딩
# - transform_features(): 위 함수들을 순차 적용하는 최종 함수
# -----------------------------------------------------------
from sklearn.preprocessing import LabelEncoder
def fillna(df):
"""결측값(NaN)을 적절한 값으로 채우는 함수"""
df["Age"].fillna(df["Age"].mean(), inplace=True)
df["Cabin"].fillna("N", inplace=True)
df["Embarked"].fillna("N", inplace=True)
return df
def drop_features(df):
"""모델 성능에 크게 기여하지 않거나 ID성 컬럼 제거"""
# PassengerId, Name, Ticket은 직접적인 예측에 필요 없다고 판단
df.drop(["PassengerId", "Name", "Ticket"], axis=1, inplace=True, errors="ignore")
return df
def format_features(df):
"""문자열 범주형 컬럼을 숫자로 변환(Label Encoding)"""
# Cabin이 여전히 문자열이면 앞 글자만 사용 (객실 등급 느낌만 반영)
if df["Cabin"].dtype == "object":
df["Cabin"] = df["Cabin"].str[:1]
# 레이블 인코딩 대상 컬럼
features = ["Cabin", "Sex", "Embarked"]
for col in features:
le = LabelEncoder()
# 각 컬럼의 고유한 값을 학습
le.fit(df[col])
# 학습된 인코더로 문자열 → 정수 변환
df[col] = le.transform(df[col])
return df
def transform_features(df):
"""위의 전처리 함수들을 순차적으로 적용하는 최종 파이프라인"""
df = fillna(df)
df = drop_features(df)
df = format_features(df)
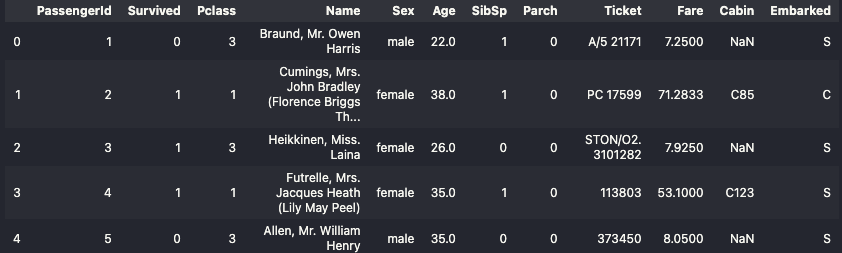
return df전처리 파이프라인을 호출하여 실제로 적용해 봅니다.
# 전처리 파이프라인 테스트
titanic_df_processed = transform_features(titanic_df.copy())
titanic_df_processed.head(10)

4. 학습 데이터 준비 및 세 가지 모델 학습·비교
# -----------------------------------------------------------
# 7. 타깃/피처 분리 및 전처리 적용
# -----------------------------------------------------------
# 원본 학습 데이터를 다시 로딩 (실습 일관성 유지용)
titanic_df = pd.read_csv("./titanic/titanic_train.csv")
# 타깃(레이블)과 피처 분리
y_titanic_df = titanic_df["Survived"]
X_titanic_df = titanic_df.drop("Survived", axis=1)
# 피처 데이터에 전처리 파이프라인 적용
X_titanic_df = transform_features(X_titanic_df)
# 확인
X_titanic_df.head(3)
# -----------------------------------------------------------
# 8. 학습/테스트 데이터 분리
# -----------------------------------------------------------
from sklearn.model_selection import train_test_split
# test_size=0.2 → 20%를 테스트 데이터로 사용
X_train, X_test, y_train, y_test = train_test_split(
X_titanic_df,
y_titanic_df,
test_size=0.2,
random_state=11
)
4-1. 세 가지 모델 생성 및 학습
# -----------------------------------------------------------
# 9. 세 가지 분류 모델 생성
# -----------------------------------------------------------
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 결정트리
dt_clf = DecisionTreeClassifier(random_state=11)
# 랜덤포레스트
rf_clf = RandomForestClassifier(random_state=11)
# 로지스틱 회귀
# solver='liblinear' : 작은 데이터셋에서 자주 사용하는 최적화 알고리즘
lr_clf = LogisticRegression(solver='liblinear')
# -----------------------------------------------------------
# 10. 각 모델 학습 및 예측, 정확도 평가
# -----------------------------------------------------------
# 1) Decision Tree
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
dt_score = accuracy_score(y_test, dt_pred)
# 2) Random Forest
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
rf_score = accuracy_score(y_test, rf_pred)
# 3) Logistic Regression
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
lr_score = accuracy_score(y_test, lr_pred)
print("=== 단일 홀드아웃 검증 결과 (교차검증 전) ===")
print(f"Decision Tree 정확도 : {dt_score:.4f}")
print(f"Random Forest 정확도 : {rf_score:.4f}")
print(f"Logistic Regression 정확도 : {lr_score:.4f}")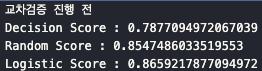
5. K-Fold 교차검증 직접 구현
# -----------------------------------------------------------
# 11. K-Fold 교차검증 함수 구현
# -----------------------------------------------------------
from sklearn.model_selection import KFold
def exec_kfold(clf, folds=5):
"""주어진 분류기(clf)에 대해 K-Fold 교차검증을 수행하는 함수"""
kfold = KFold(n_splits=folds, shuffle=True, random_state=11)
scores = []
for fold_idx, (train_index, test_index) in enumerate(kfold.split(X_titanic_df), start=1):
# KFold가 나누어준 인덱스를 이용해 학습/검증 데이터 분할
X_train_k, X_test_k = X_titanic_df.values[train_index], X_titanic_df.values[test_index]
y_train_k, y_test_k = y_titanic_df.values[train_index], y_titanic_df.values[test_index]
# 모델 학습
clf.fit(X_train_k, y_train_k)
# 예측 수행
predictions = clf.predict(X_test_k)
# 정확도 계산
accuracy = accuracy_score(y_test_k, predictions)
scores.append(accuracy)
print(f"[Fold {fold_idx}] 정확도: {accuracy:.4f}")
# 모든 Fold에 대한 평균 정확도
mean_score = np.mean(scores)
print(f"\n=> 평균 K-Fold 정확도: {mean_score:.4f}")
# 결정트리에 대해 K-Fold 실행
exec_kfold(dt_clf, folds=5)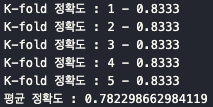
6. cross_val_score()로 교차검증 간편하게 수행
# -----------------------------------------------------------
# 12. cross_val_score()를 이용한 교차검증
# -----------------------------------------------------------
from sklearn.model_selection import cross_val_score
# Decision Tree 모델에서 5-Fold 교차검증 수행
scores = cross_val_score(dt_clf, X_titanic_df, y_titanic_df, cv=5, scoring="accuracy")
print("=== cross_val_score 결과 ===")
for fold_idx, accuracy in enumerate(scores, start=1):
print(f"[Fold {fold_idx}] 정확도: {accuracy:.4f}")
print(f"\n=> 평균 cross_val_score 정확도: {np.mean(scores):.4f}")
7. GridSearchCV로 하이퍼파라미터 튜닝
마지막으로, 결정트리 모델의 성능을 높이기 위해 GridSearchCV로
max_depth, min_samples_split, min_samples_leaf 조합을 탐색해 보겠습니다.
# -----------------------------------------------------------
# 13. GridSearchCV를 이용한 하이퍼파라미터 튜닝
# -----------------------------------------------------------
from sklearn.model_selection import GridSearchCV
# 탐색할 하이퍼파라미터 그리드 정의
parameters = {
"max_depth": [2, 3, 5, 10],
"min_samples_split": [2, 3, 5],
"min_samples_leaf": [1, 5, 8]
}
# GridSearchCV 설정
grid_dclf = GridSearchCV(
estimator=dt_clf, # 기준 모델
param_grid=parameters, # 하이퍼파라미터 후보군
scoring="accuracy", # 정확도를 기준으로 평가
cv=5, # 5-Fold 교차검증
refit=True # 최적 파라미터로 전체 학습 데이터 재학습
)
# 학습 수행 (X_train, y_train 기준)
grid_dclf.fit(X_train, y_train)
# 최적의 하이퍼파라미터 조합
print("GridSearchCV 최적 하이퍼 파라미터:", grid_dclf.best_params_)
# 해당 파라미터 조합에서의 교차검증 최고 정확도
print("GridSearchCV 최고 교차검증 정확도:", grid_dclf.best_score_)
7-1. 최적 모델로 테스트 데이터 평가
# -----------------------------------------------------------
# 14. 최적 하이퍼파라미터 모델로 최종 테스트 평가
# -----------------------------------------------------------
# best_estimator_: 최적 파라미터로 이미 학습된 모델
best_dclf = grid_dclf.best_estimator_
# 테스트 데이터에 대한 예측 수행
dpredictions = best_dclf.predict(X_test)
# 정확도 평가
accuracy = accuracy_score(y_test, dpredictions)
print(f"최적 결정트리 모델의 테스트 데이터 정확도: {accuracy:.4f}")
이로써 타이타닉 생존 예측 문제에 대해 전처리 → 여러 모델 비교 → 교차검증 → 하이퍼파라미터 튜닝 → 최종 평가까지 전체 머신러닝 파이프라인이 완성되었습니다.
결론: 전체 개념 정리 & 개념 퀴즈와 연결하기
마지막으로, 지금까지 1~6편에서 다룬 핵심 개념을
사용자님이 첨부하신 퀴즈 이미지 흐름에 맞춰 정리하면서 마무리하겠습니다.
- 모델 학습에 사용되는 입력 데이터는? → 피처(Feature)
- 모델이 패턴을 학습하는 데 사용하는 독립변수, 속성입니다.
- 사이킷런에서 학습과 예측의 핵심 메서드 → fit()과 predict()
- fit()으로 학습, predict()로 예측을 수행합니다.
- 과적합을 막기 위한 가장 중요한 원칙 → 테스트 데이터는 학습에 사용하지 않는다
- 학습에 사용되지 않은 별도의 테스트 세트로 성능을 평가해야 공정합니다.
- 불균형 분포에서 레이블 비율을 유지하며 교차검증 → Stratified K-Fold
- 각 폴드의 레이블 비율을 원본 데이터와 유사하게 유지합니다.
- Max_depth, Min_samples_split 등의 최적 조합을 찾는 과정 → 하이퍼파라미터 튜닝
- 모델 외부 설정값을 조정하여 성능을 최적화하는 과정입니다.
- 텍스트/범주형 데이터를 숫자로 바꾸는 작업 → 데이터 인코딩(Data Encoding)
- Label Encoding, One-Hot Encoding 등이 포함됩니다.
- Label Encoding의 순서 문제를 해결하는 방식 → One-Hot Encoding
- 각 범주를 별도 벡터로 만들어 순서 의미를 없앱니다.
- 피처들의 값 범위를 맞춰 특정 피처에 치우치지 않게 하는 과정 → 데이터 스케일링(Data Scaling)
- 특히 선형 모델, SVM, 신경망 등에서 매우 중요합니다.
- StandardScaler가 사용하는 방식 → Z-score 표준화
- 평균을 0, 분산을 1로 맞추어 표준 정규분포 형태로 변환합니다.
- 스케일링의 올바른 절차 → 학습 데이터에만 fit(), 학습/테스트 모두에 transform()
- 스케일러도 일종의 모델이므로, 학습 데이터 통계(평균/표준편차)를 기준으로
테스트 데이터는 transform()만 적용해야 데이터 누수를 막을 수 있습니다.
- 스케일러도 일종의 모델이므로, 학습 데이터 통계(평균/표준편차)를 기준으로
타이타닉 실습을 끝까지 따라오셨다면,
이 10개의 개념 퀴즈는 머릿속에서 자연스럽게 정답이 떠오르는 상태가 되었을 것입니다.
이제 이 기본기를 바탕으로,
실제 업무 데이터나 개인 프로젝트에 적용하면서 자신만의 머신러닝 파이프라인을 만들어보시면 좋겠습니다.
'Programming' 카테고리의 다른 글
| [분류 성능 평가지표 1편] 정확도(Accuracy)는 왜 조심해서 봐야 할까? (0) | 2025.12.13 |
|---|---|
| ChromeDriver 버전 불일치로 발생하는 SessionNotCreatedException 해결 방법(undetected-chromedriver 기준) (0) | 2025.12.10 |
| [5편] 머신러닝 데이터 전처리 기본기: 인코딩·스케일링 실습 정리개요 (0) | 2025.12.10 |
| [4편] cross_val_score와 GridSearchCV: 교차검증 자동화 및 하이퍼파라미터 튜닝 (0) | 2025.12.09 |
| [3편] 교차검증(K-Fold, Stratified K-Fold)으로 모델 성능을 더 정확하게 평가하기 (0) | 2025.12.09 |