

머신러닝 모델을 만든 뒤 반드시 해야 하는 단계가 있습니다.
바로 **평가(Evaluation)**입니다.
아무리 복잡한 모델을 사용해도, “우리 모델이 실제로 얼마나 잘 예측하는가?”를 판단할 수 없다면 의미가 없습니다.
특히 분류(Classification) 문제와 회귀(Regression) 문제는 예측 방식뿐 아니라 평가하는 방식도 완전히 다릅니다.
이번 글은 머신러닝 시리즈의 마지막 편으로,
지금까지 배운 모델들을 어떻게 평가해야 하는지 핵심 지표만 정리해드립니다.
1. 분류 모델 평가 지표 (Classification Metrics)
분류 문제는 정답이 카테고리 형태일 때 사용합니다.
예: 생존/사망, 스팸/정상, 구매/비구매 등
모든 분류 평가 지표의 기반이 되는 네 가지 값부터 정리합니다.
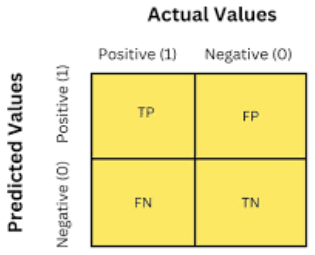
| TP (True Positive) | 실제 Positive를 맞게 예측 |
| TN (True Negative) | 실제 Negative를 맞게 예측 |
| FP (False Positive) | 실제 Negative인데 Positive로 잘못 예측 |
| FN (False Negative) | 실제 Positive인데 Negative로 잘못 예측 |
이 네 가지 조합으로 모든 평가 지표가 계산됩니다.
1-1. 정확도 Accuracy
가장 기본이지만 가장 오해가 많은 지표입니다.
정의
Accuracy = (TP + TN) / 전체 데이터 수설명
전체 예측 중 얼마나 맞췄는지 나타냅니다.
하지만 정확도는 불균형 데이터에서 신뢰할 수 없습니다.
예: 생존자 10%, 사망자 90%라면 모두 "사망" 예측만 해도 정확도 90%.
→ 그래서 Precision, Recall, F1이 필요합니다.
1-2. 정밀도 Precision
“Positive라고 예측한 것 중 실제 Positive의 비율”
정의
Precision = TP / (TP + FP)설명
FP(잘못된 Positive)를 얼마나 줄였는가?
예시
스팸 필터가 정상 메일을 스팸으로 잘못 분류하지 않는지 판단할 때 중요
1-3. 재현율 Recall (민감도)
“실제 Positive 중에서 모델이 맞춘 비율”
정의
Recall = TP / (TP + FN)설명
FN(놓친 Positive)을 얼마나 줄였는가?
예시
암 진단 모델에서 암 환자를 놓치면 안 되므로 Recall이 중요
1-4. F1 Score
정밀도와 재현율의 조화 평균.
불균형 데이터에 가장 많이 쓰이는 지표입니다.
정의
F1 = 2 × (Precision × Recall) / (Precision + Recall)설명
정밀도 또는 재현율 하나만 좋은 모델을 피하고,
두 지표를 균형 있게 평가할 수 있습니다.
1-5. ROC-AUC
Positive vs Negative를 얼마나 잘 구분하는지 측정하는 종합 지표입니다.
- ROC 곡선: TPR(Recall) vs FPR 그래프
- AUC: ROC 아래 면적
- 값 범위: 0 ~ 1
- 1에 가까울수록 좋은 모델
AUC 0.90 이상 = 매우 뛰어난 분류 모델
2. 회귀 모델 평가 지표 (Regression Metrics)
회귀 문제는 연속적인 수치 예측에서 사용합니다.
예: 가격 예측, 수요 예측, 온도 예측 등
2-1. MAE (Mean Absolute Error)
“평균적으로 얼마나 틀렸는가?”
정의
MAE = 평균(|예측값 - 실제값|)특징
- 해석이 직관적
- 이상치(Outlier)에 덜 민감
2-2. MSE (Mean Squared Error), RMSE (Root MSE)
MSE 정의
MSE = 평균((예측값 - 실제값)²)RMSE 정의
RMSE = sqrt(MSE)특징
- RMSE는 실제 단위로 해석 가능
- 이상치가 있으면 오차가 더 크게 반영됨(민감함)
실무에서는 RMSE를 가장 많이 사용합니다.
2-3. R² (결정계수)
“모델이 데이터를 얼마나 설명하는가?”
정의
0 ~ 1 사이의 값 (1에 가까울수록 좋음)설명
- 1.0: 완벽한 예측
- 0.0: 아무 것도 설명하지 못함
- 음수: 모델이 평균보다 못함
회귀 모델의 전반적인 설명력을 판단할 때 사용합니다.
이번 글에서는 머신러닝 모델을 평가할 때 가장 많이 사용되는 지표들을 분류와 회귀로 나누어 정리했습니다.
핵심 요약
- 분류에서는 정확도는 절대 혼자 쓰지 않는다.
- F1-score와 ROC-AUC가 실전에서 가장 많이 사용
- 회귀에서는 RMSE와 R²가 가장 중요한 지표
- 평가지표 선택은 데이터 특성과 문제 목적에 따라 달라진다
이로써 머신러닝 시리즈의 핵심 개념부터
지도학습·비지도학습·검증·튜닝·평가까지 한 번에 학습할 수 있는
6편의 시리즈가 완성되었습니다.
'Programming' 카테고리의 다른 글
| [1편] 사이킷런(scikit-learn) 이해하기: 머신러닝 기본 개념과 예제 아이리스(Iris) 소개 (0) | 2025.12.09 |
|---|---|
| 딥러닝 기초 개념과 학습 프로세스 완벽 정리 (0) | 2025.12.09 |
| 머신러닝 완전 입문 가이드 5편 : 회귀·분류 모델 하이퍼파라미터 완전 정리(Linear Regression부터 CatBoost까지) (0) | 2025.12.08 |
| 머신러닝 완전 입문 가이드 4편 : 파라미터(Parameter)와 하이퍼파라미터(Hyperparameter)의 개념과 차이 (1) | 2025.12.08 |
| 머신러닝 완전 입문 가이드 3편 : 왜 검증(Validation)이 중요한가? 검증 방식과 평가지표 완전 이해 (0) | 2025.12.08 |